5 Entscheidungsbäume
Wir lernen hier nun sogenannte Entscheidungsbäume (engl. Decision Trees) kennen. Entscheidungsbäume gehören zur Klasse der nicht-parametrischen Machine Learning Modelle (wie KNN), da die Anzahl Parameter des Modells nicht von vornherein klar ist und erst nach dem Modelltraining feststeht.
Entscheidungsbäume können sowohl für Regressions- als auch für Klassifikationsprobleme angewendet werden. Dementsprechend werden die spezifischen Modelle Regressionsbaum bzw. Klassifikationsbaum genannt. Wir werden uns hier ausführlich mit Regressionsbäumen beschäftigen und dann sehen, dass Klassifikationsbäume lediglich eine andere Kostenfunktion optimieren, aber sonst genau gleich funktionieren.
Entscheidungsbäume sind in der Praxis sehr beliebt, vorausgesetzt es geht ausschliesslich um die Interpretierbarkeit: wir werden sehen, dass Entscheidungsbäume sehr einfach und ansprechend visualisiert werden können. Wenn es allerdings darum geht, möglichst gute Vorhersagen zu machen, dann werden in der Praxis kaum Entscheidungsbäume angewendet, weil sie selten zu den am besten performenden Modellen gehören. Entscheidungsbäume gelten als instabile Modelle, d.h., sie ändern sich teilweise stark, wenn sich die Trainingsdaten verändern. Bäume haben also in der Regel hohe Varianz und wenig Bias (Bias-Variance Tradeoff). Wir werden aber in Kapitel 6 sehen, dass in der Praxis gut performende Modelle (sogenannte Ensemble Methoden) auf individuellen Entscheidungsbäumen aufbauen.
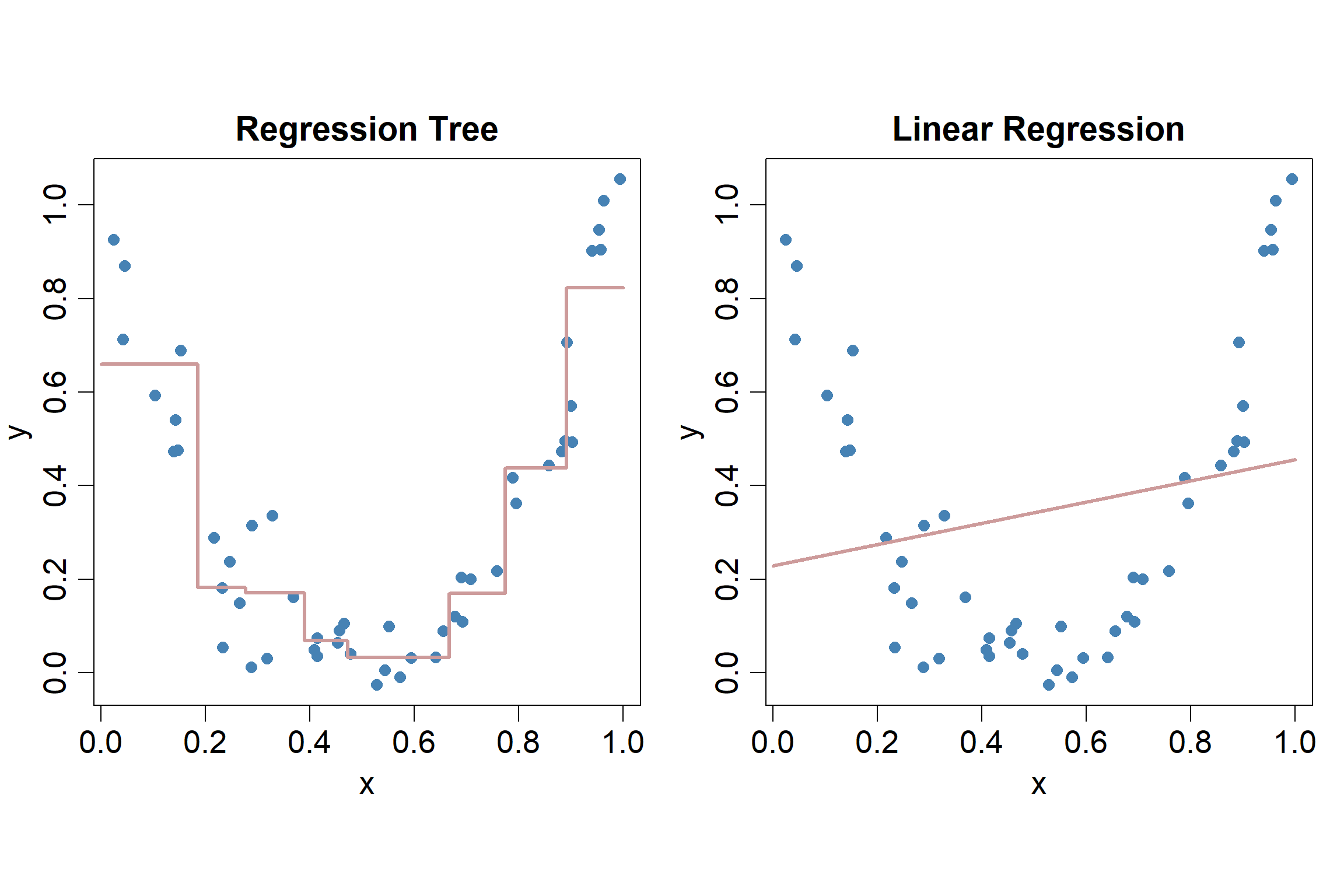
Um eine erste Intuition aufzubauen, schauen wir uns in folgender Abbildung den visuellen Unterschied zwischen dem Linearen Regressionsmodell (Kapitel 2) und einem Entscheidungsbaum für das Regressionsproblem mit einer Input-Variable \(x_i\) an:
Wie den Streudiagrammen entnommen werden kann, ist der wahre Zusammenhang zwischen dem Input \(x_i\) und der Outputvariable \(y_i\) hier stark nicht-linear. Der Fit des linearen Regressionsmodells (rechter Plot) ist sehr schlecht, während ein Regressionsbaum zu einem relativ guten Fit führt (linker Plot). Wir können davon bereits ableiten, dass Entscheidungsbäume flexibler sind als das lineare Regressionsmodell. Dementsprechend wird die Gefahr des Overfittings bei Entscheidungsbäumen auch grösser sein als beim linearen Regressionsmodell.
Dieses Kapitel ist teilweise inspiriert durch (James u. a. 2021, Kap. 8) und (Géron 2022, Kap. 6).
5.1 Regressionsbäume
Wir widmen uns in einem ersten Schritt kurz der “Anatomie” von Entscheidungsbäumen. Danach überlegen wir uns, wie ein trainierter Entscheidungsbaum gelesen werden muss, so dass wir verstehen, wie das Modell Vorhersagen macht. In einem dritten Abschnitt befassen wir uns mit dem Modelltraining. Zu guter Letzt schauen wir uns noch kurz die mathematische Modellspezifikation an.
5.1.1 Anatomie eines Entscheidungsbaums
Warum spricht man bei diesem Modell überhaupt von Bäumen? Weil die Visualisierung des Modells wie ein umgekehrter Baum aussieht (siehe Abbildung unten). Dementsprechend haben die verschiedenen Teile des “Baums” auch botanisch-inspirierte Namen.
Wir haben einen obersten Knoten, der Root Node genannt wird. Die inneren Knoten, nach denen weitere Splits folgen, werden Internal Nodes genannt. Die untersten Knoten, nach denen keine weiteren Splits folgen, werden Leaf Nodes genannt. Die Nodes sind durch sogenannte Branches verknüpft. Die Tiefe eines Baums entspricht der Anzahl von Ebenen, auf denen Splits durchgeführt werden.
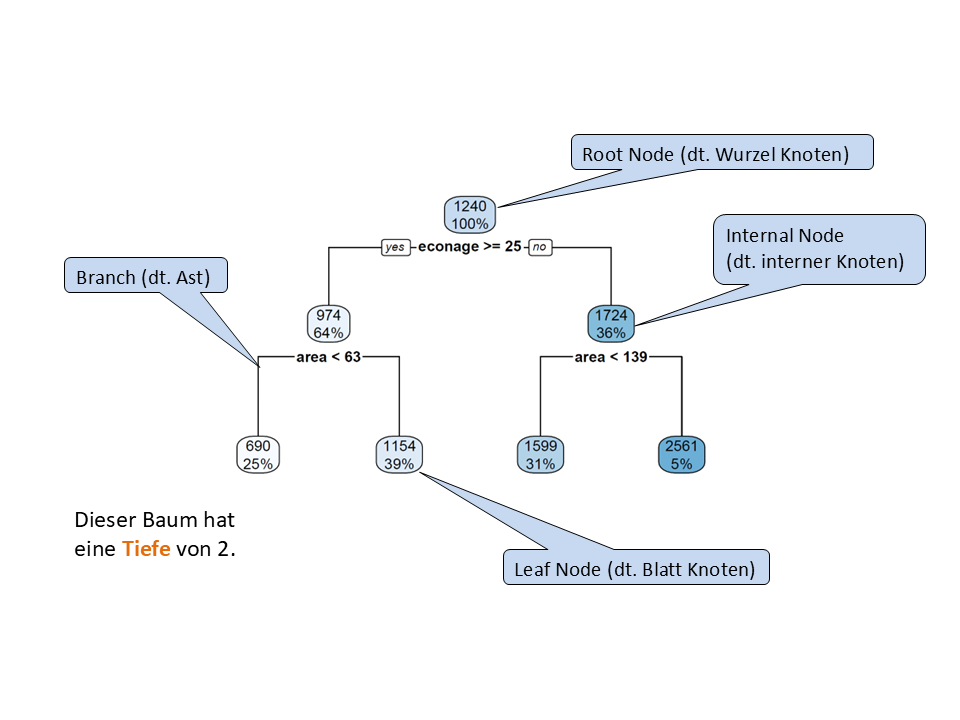
econage) und der Fläche (area) vorherzusagen.
Doch was repräsentiert dieser Baum eigentlich? Der Baum repräsentiert eine Sequenz von Splitting-Regeln basierend auf den Input-Variablen. Wir können eine gegebene Beobachtung \(\mathbf{x}_i\) vom Root Node aus durch den Baum “schicken”. Bei jedem Node im Baum wird die Beobachtung basierend auf dem konkreten Input-Variablenwert entweder links oder rechts runtergeschickt. So endet die Beobachtung irgendwann in einem Leaf Node.
Etwas mathematischer ausgedrückt: der Baum repräsentiert eine Segmentierung des Input Spaces in simple, rechteckige Regionen. Wir werden das im nächsten Abschnitt anhand eines Beispiels demonstrieren.
5.1.2 Wie liest man einen Baum?
Wir verwenden hier in der Folge den housingrents Datensatz, der \(n = 152\) Beobachtungen zu Schweizer Wohnungen enthält. Die Outputvariable ist die Miete (rent). Die zwei wichtigsten Input-Variablen sind die Fläche einer Wohnung (area) sowie das ökonomische Alter einer Wohnung (econage). Eine weitere Input-Variable ist nre, dabei handelt es sich um eine binäre kategorische Variable, die den Wert 1 annimmt, falls eine Wohnung der Immobilienfirme NRE gehört und sonst 0. Der Datensatz ist im Dataframe df. Hier sind die ersten 6 Zeilen im Datensatz:
head(df) id rooms area rent nre econage balcony
1 1 1 34 310 0 35 yes
2 2 1 35 749 0 44 no
3 3 1 50 281 0 23 yes
4 4 1 45 483 0 35 no
5 5 4 75 1510 0 32 no
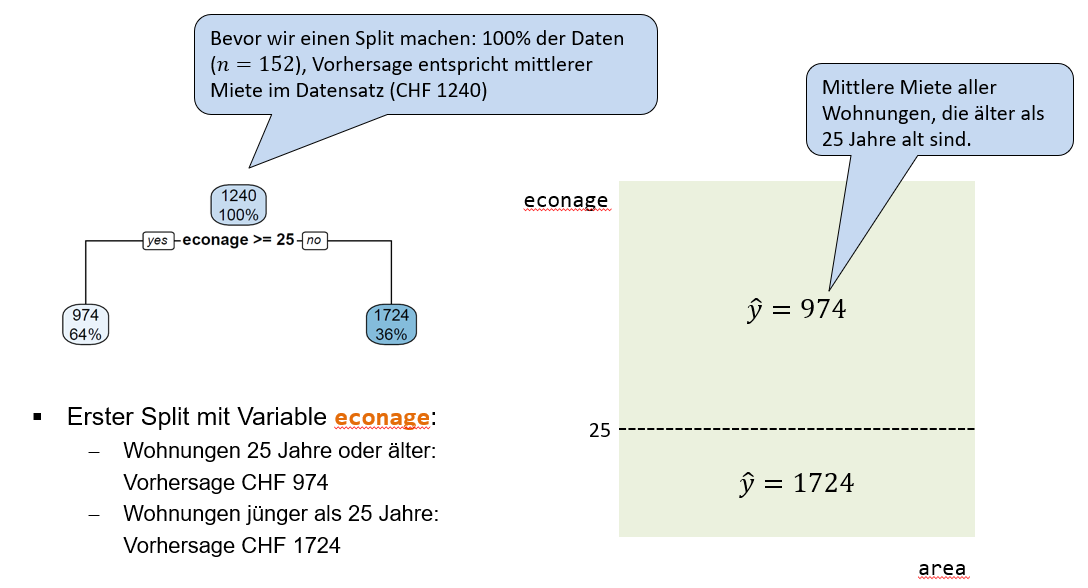
6 6 1 35 515 0 43 noDie Abbildung 5.2 (links) zeigt den Root Node sowie den ersten Split des Baums, der resultiert, wenn ein Regressionsbaum auf den housingrents Daten angewendet wird. Der Root Node enthält zwei Zahlen, einerseits die mittlere Miete über den ganzen Trainingsdatensatz (CHF 1240) und andererseits den Anteil von Trainingsbeobachtungen im Root Node. Dieser Anteil ist vor dem ersten Split noch 100%.
Der erste Split verwendet die Variable econage und den Splitpunkt 25. Alle Wohnungen, die min. 25 Jahre alt sind, gehen dem linken Branch entlang in den linken internen Node. Insgesamt landen so 64% der Trainingsbeobachtungen in diesem linken internen Node. Die durchschnittliche Miete für diese Beobachtungen beträgt CHF 974. Alle Wohnungen, die jünger als 25 Jahre alt sind, gehen dem rechten Branch entlang in den rechten internen Node. Das sind dementsprechend die restlichen 36% der Beobachtungen und deren mittlere Miete beträgt CHF 1724.
Wichtig: dieser erste Split segmentiert den Input Space nun in zwei Regionen (Rechtecke), wie im rechten Teil der Abbildung dargestellt. Das wichtigste Take-Away hier ist, dass ein Split im Baum einer Segmentierung des Input Spaces entspricht! Weil wir hier nur die Variablen econage und area betrachten, können wir diesen Input Space ohne Probleme in 2D visualisieren.
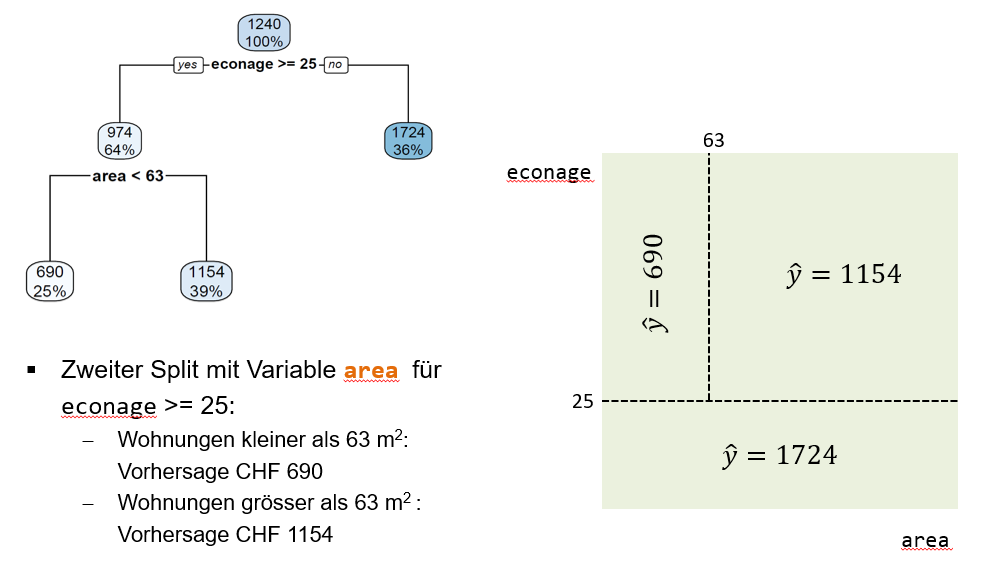
Der zweite Split geschieht beim linken internen Node (Abbildung 5.3). Dort splitten wir die 64% der Beobachtungen basierend auf der Input-Variable area in zwei Untergruppen. Der Splitpunkt liegt bei 63 Quadratmeter. Der linke Leaf Node enthält nun nur noch 25% der Beobachtungen und deren mittlere Miete beträgt CHF 690. Das macht Sinn, denn es handelt sich dabei um alte (25 Jahre oder älter) und kleine Wohnungen (kleiner als 63 Quadratmeter). Der rechte Leaf Node enthält 39% aller Beobachtungen und deren Mittelwert beträgt CHF 1154. Es handelt sich dabei um alte, aber relativ grosse Wohnungen.
Im rechten Teil der Abbildung sehen wir, dass dieser zweite Split den oberen Teil des Input Spaces weiter segmentiert in zwei Subregionen.
Der dritte Split geschieht im rechten internen Node und basiert ebenfalls auf der Input-Variable area (Abbildung 5.4). Der Splitpunkt liegt bei 139 Quadratmeter. Dieser Split teilt also die eher neuen Wohnungen (erster Split) weiter auf in sehr grosse (grösser als 139 Quadratmeter) und weniger grosse (kleiner als 139 Quadratmeter) Wohnungen. Die mittlere Miete für die 31% der Beobachtungen im linken Leaf Node beträgt CHF 1599, während die mittlere Miete für die 5% der Beobachtungen im rechten Leaf Node CHF 2561 beträgt. Der dritte Split segmentiert das untere Reckteck im Input Space weiter.
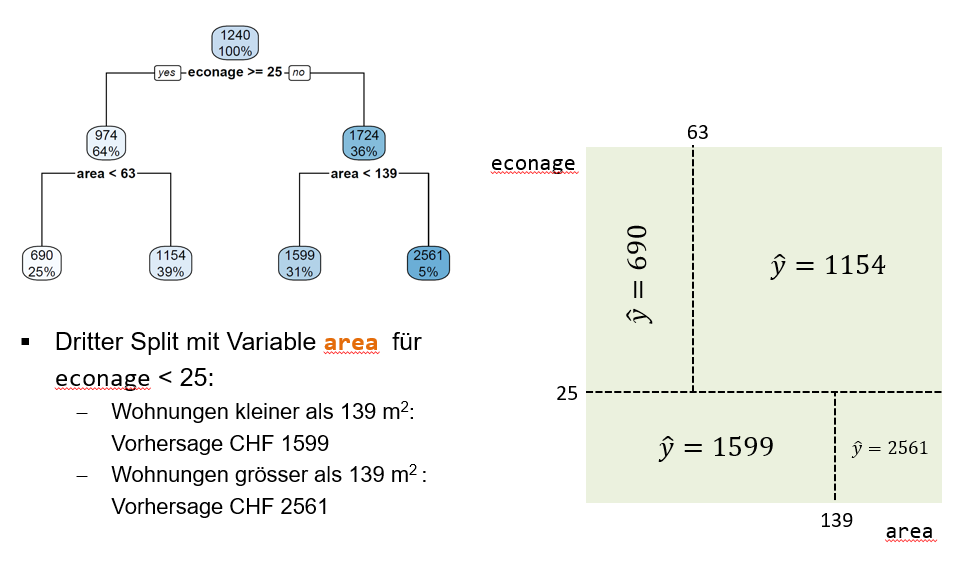
Der finale Baum sowie die finale Segmentierung des Input Spaces sehen wie folgt aus:
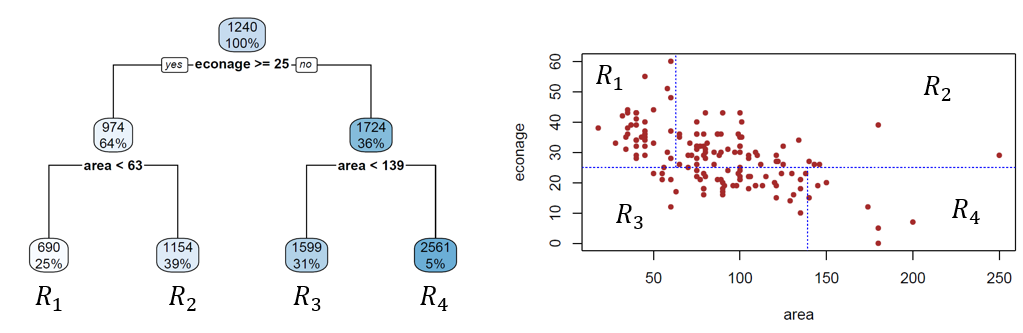
Wir sehen, dass die drei Splits zu vier Leaf Nodes führen.
HinweisDecision Boundaries von Entscheidungsbäumen
Jeder Leaf Node entspricht einer Region im Input Space. Die blau gestrichelten Linien (Abbildung 5.5), welche die Regionen voneinander trennen, sind die Decision Boundaries dieses Modells. Sie begrenzen die verschiedenen Regionen, in denen wir je unterschiedliche Vorhersagen machen.
Die Vorhersagen unseres Baums sind nichts anderes als die mittleren Mieten in den jeweiligen Regionen. Überlegen wir uns das kurz anhand eines Beispiels: wir haben nun eine 15-jährige Wohnung mit einer Fläche von 110 Quadratmeter. Gemäss unserem Baum gehört diese Wohnung der Region \(R_3\) an und dementsprechend wäre unsere Vorhersage für diese Wohnung CHF 1599. Dabei sehen wir gleich noch eine andere Eigenschaft von Entscheidungsbäumen: sie machen für alle Beobachtungen in derselben Region die gleiche Vorhersage. Oder in anderen Worten: die Vorhersagen sind pro Region konstant.
Fragen
- Was ist die Tiefe des nachfolgend abgebildeten Regressionsbaums?
- Was würde der abgebildete Regressionsbaum für eine Wohnung mit \(econage=28\), \(area=98\) und \(rooms=4\) vorhersagen?
- Wie viele Entscheidungsregionen resultieren aus dem Regressionsbaum?
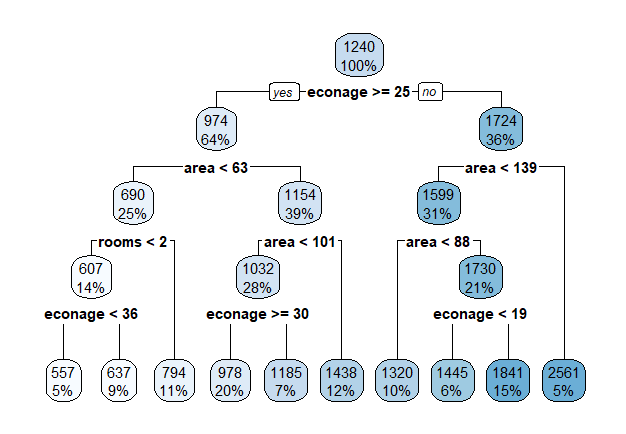
R trainierten Baums auf dem housingrents Datensatz.
TippLösung
- Die Tiefe des Baums ist 4.
- Die Vorhersage für diese Wohnung wäre eine Miete von CHF 1185.
- Der Baum hat 10 Entscheidungsregionen, weil der Baum 10 Leaf Nodes hat.
5.1.3 Modelltraining
Nun haben wir oben bereits gesehen, wie ein fertig trainierter Entscheidungsbaum aussieht, wie er interpretiert werden muss und wie man damit Vorhersagen machen kann. Doch wie wird das Modell trainiert?
Das Ziel ist, einen Regressionsbaum zu finden, dessen Entscheidungsregionen zu einer Minimierung des Mean Squared Errors (MSE) führen. Wie bei der linearen Regression (Kapitel 2) ist also auch hier der MSE die Kostenfunktion, die es zu minimieren gilt.
Weil ein Regressionsbaum in jeder Region die gleichen Vorhersagen macht, schreiben wir die Kostenfunktion hier in einer speziellen Form auf:
\[ J = \frac{1}{n} \sum_{k=1}^K \sum_{i \in R_k} \left(y_i - \hat{y}_{R_k}\right)^2 \]
Die äussere Summe summiert über die Regionen \(R_1, R_2, \dots, R_K\) und die innere Summe summiert für jede Region über die quadrierten Distanzen zwischen beobachteten und vorhergesagten Werten der Outputvariable. Ich hoffe, Sie sehen, dass es sich wirlich nur um den MSE handelt, einfach etwas speziell geschrieben wegen den Entscheidungsregionen des Baums.
Leider ist es hier nicht möglich dieses Minimierungsproblem genau (also analytisch) zu lösen, denn es gibt zu viele verschiedene (genauer gesagt: unendlich viele) Möglichkeiten, wie die Recktecke im Input Space angeordnet und kombiniert werden können.
Beim Training von Entscheidungsbäumen treffen wir deshalb einige vereinfachende Annahmen, um eine Annäherung an die optimale Lösung für das Minimum der Kostenfunktion zu finden. Der Trainingsalgorithmus wird Recursive Binary Splitting genannt. Dieser Algorithmus hat die Eigenschaft, dass er greedy ist. Doch was bedeutet all das?
- Binary: Jeder Split hat genau einen Splitpunkt und führt deshalb zu genau zwei “Child Nodes”. Jeder Split entspricht also einer binären “entweder-oder” Entscheidung. Es gibt aus einem Split nur zwei mögliche Branches (und nicht drei, vier, oder mehr), die nach unten führen.
- Recursive: Jeder Split basiert auf dem vorangegangenen Split ein Level höher. Der zweite Split splittet also eine der resultierenden Regionen aus dem ersten Split. Wenn Sie nochmal zum zweiten Split beim
housingrentsDatensatz gehen, dann sehen Sie, dass der zweite Split lediglich die obere Region splittet und nicht den ganzen Input Space. Der zweite Split bezieht sich auf den ersten Split, ist also rekursiv. - Greedy: wir optimieren in jedem Knoten immer nur den nächstmöglichen Split und schauen nicht weiter voraus bzw. den Baum runter. Der Algorithmus ist also in einem gewissen Sinn “geizig”.
Am besten schauen wir uns diesen Trainingsalgorithmus wiederum anhand des housingrents Datensatzes an:
- Wir rechnen den Wert der Kostenfunktion für jede Input-Variable und alle möglichen Splitpunkte \(s\) und wählen diejenige Input-Variable mit Splitpunkt \(s\), wo \(J\) minimal ist. Wir sehen, dass
econagemit \(s=25\) zum kleinsten Wert für \(J\) führt. Darum ist dies unser erster Split im Baum. Gleichzeitig können wir daraus ableiten, dasseconagedie wichtigste Input-Variable im Datensatz ist. Nachfolgend die Kostenfunktionswerte für ein paar mögliche Splitpunkte:econagemit \(s=25\): \(MSE = 331'686.3\)
areamit \(s=63\): \(MSE = 359'049\)
nremit \(s=0.5\): \(MSE = 439'140.2\) (Schnittpunkt \(s=0.5\) teilt die Beobachtungen in NRE und nicht-NRE)- Viele weitere Möglichkeiten…
- Basierend auf den zwei Regionen aus dem ersten Split, wählen wir den zweiten Split so, dass wiederum \(J\) minimiert wird. Es resultieren drei Regionen. Wir sehen, dass
areamit \(s=63\) der nächstbeste Split ist.areamit \(s=63\): \(MSE = 298'849\)
nremit \(s=0.5\): \(MSE = 328'305\)- Viele weitere Möglichkeiten…
- Wir können so fortfahren bis ein Stoppkriterium erfüllt ist (z.B. maximale Tiefe des Baums erreicht).
Dieser Trainingsalgorithmus hat ein grosses Problem und zwar führt er zu einer krassen Form von Overfitting. Wenn wir den Algorithmus nicht begrenzen, dann splittet der Baum frisch fröhlich weiter bis er irgendwann so viele Leaf Nodes wie Beobachtungen hat und jeder Leaf Node genau den Wert der Trainingsbeobachtung vorhersagt. Der Baum hat dann zwar einen Kostenfunktionswert von 0 auf dem Trainingsdatensatz, würde auf einem Testdatensatz jedoch katastrophal schlechte Vorhersagen machen.
Die Lösung ist in der Praxis zum Glück einfach: wir müssen die Komplexität des Baums mittels eines Stoppkriteriums beschränken (siehe Schritt 3 im obigen Algorithmus). Folgende Kriterien zur Beschränkung sind möglich:
- Maximale Tiefe des Baums
- Minimale Anzahl Beobachtungen in einem Leaf Node
- Minimale Anzahl Beobachtungen in einem Internen Node
- Maximale Anzahl Leaf Nodes
- Viele weitere…
HinweisHyperparameter von Entscheidungsbäumen
All die oben aufgelisteten Stoppkriterien können wir als Hyperparameter unseres Modells interpretieren und dementsprechend können wir den optimalen Wert für ein gegebenes Stoppkriterium mittels Hyperparameter Tuning bestimmen. Eine alternative Lösung, welche in der Literatur manchmal besprochen wird, wäre Tree Pruning.
In nachfolgender Abbildung trainieren wir einen Regressionsbaum auf einem simplen Datensatz mit einer Input-Variable. Wir beschränken den Baum mittels der minimalen Anzahl Beobachtungen in einem internen Knoten (minsize im R-Package tree). Wenn dieses Kriterium auf 2 gesetzt wird, dann kann der resultierende Baum die Daten perfekt abbilden.
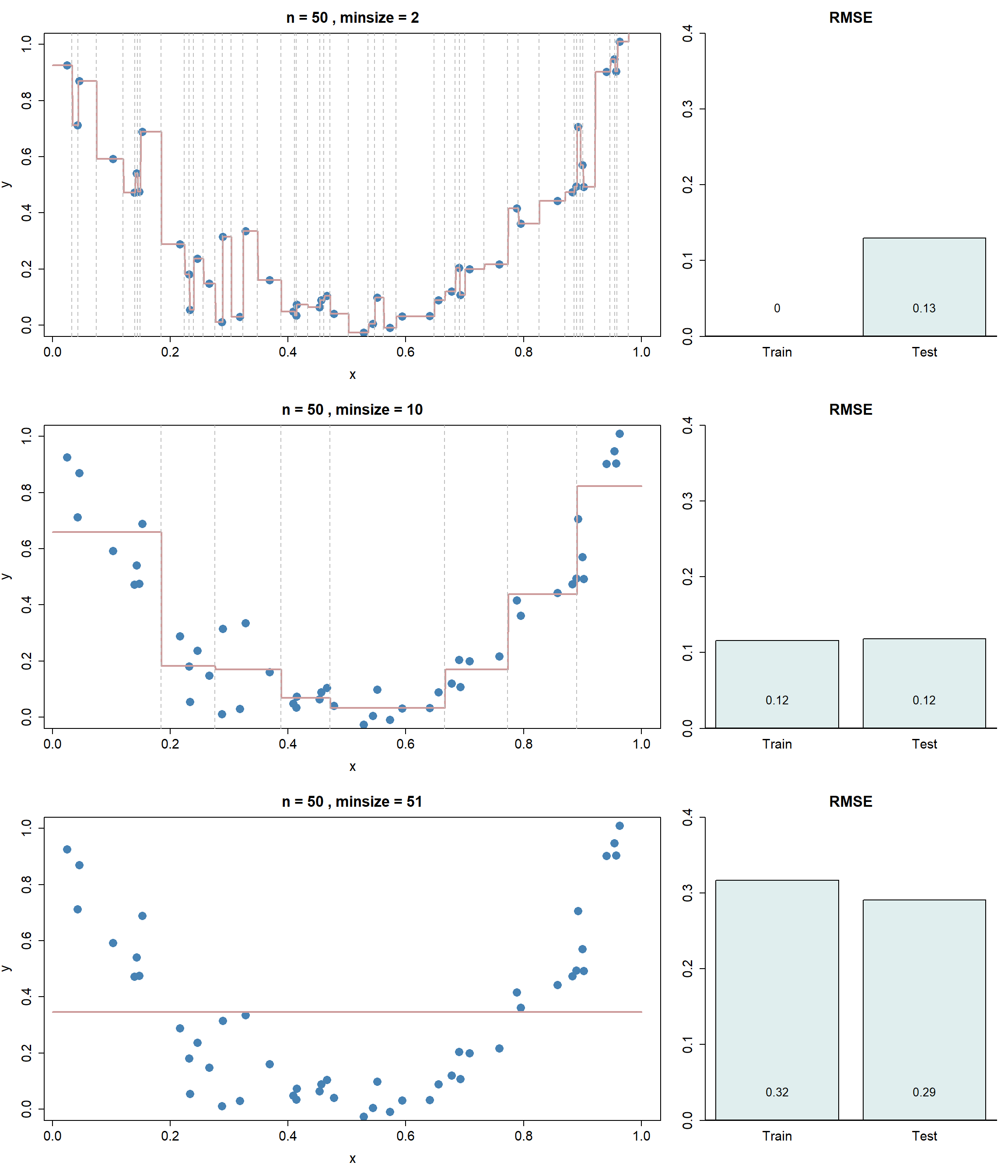
Fragen
- Welche der obigen Abbildungen repräsentiert Overfitting?
- Welche Underfitting?
TippLösung
- Die erste Abbildung ist ein klares Beispiel von Overfitting. Der Baum darf so lange weiter splitten, bis interne Nodes nur noch minimal zwei Beobachtungen enthalten. Weil die Beschränkung für interne Nodes gilt, heisst das, dass die danach folgenden Leaf Nodes nur noch je eine Beobachtung enthalten. Der Datensatz wurde so segmentiert, dass jede Entscheidungsregion nur noch eine Trainingsbeobachtung enthält. Dementsprechend ist der RMSE auf den Trainingsdaten 0.
- Die letzte Abbildung ist ein klares Beispiel von Underfitting. In diesem Fall müssen interne Nodes mindestens 51 Beobachtungen enthalten. Mit \(n=50\) darf das Modell dementsprechend nicht mal nach dem Root Node einen ersten Split machen. Das führt zu einer einzigen Entscheidungsregion, nämlich dem ganzen Wertebereich von \(x\). Und überall wird \(\bar{y}\), also der Mittelwerte über die Outputwerte im Traininsdatensatz vorhergesagt.
5.1.4 Modellspezifikation
Wir hatten in diesem Abschnitt im Vergleich zu vorherigen Kapitel eine etwas komische Reihenfolge und kommen nun erst zum Schluss auf die Modellspezifikation zu sprechen. Auch dieses nicht-parametrische Modell kann mathematisch spezifiziert werden und zwar wie folgt:
\[ f(\mathbf{x}_i) = \sum_{k=1}^K \hat{y}_{R_k} \cdot \mathbb{1}_{\{\mathbf{x}_i \in R_k\}} \]
Wir summieren also über die Entscheidungsregionen \(R_k\). \(\hat{y}_{R_k}\) ist der Durchschnitt über die Werte der Outputvariable der Trainingsbeobachtungen in Region \(k\). Die Funktion \(\mathbb{1}_{\{\mathbf{x}_i \in R_k\}}\) ist die sogenannte Indikatorfunktion, die nur genau dann den Wert 1 annimmt, wenn die Beobachtung \(\mathbf{x}_i\) in Region \(R_k\) liegt.
Beispiel: wir haben drei Regionen \(R_1, R_2, R_3\) mit entsprechenden Mittelwerten \(\hat{y}_{R_1}=500\), \(\hat{y}_{R_2}=750\) und \(\hat{y}_{R_3}=1000\). Nun haben wir eine neue Beobachtung \(\mathbf{x}_i\), die gemäss unserem Baum der Region 2 angehört. Der Funktionswert ist dementsprechend:
\[ \hat{f}(\mathbf{x}_i) = 500 \cdot 0 + 750 \cdot 1 + 1000 \cdot 0 = 750 \]
5.2 Klassifikationsbäume
Klassifikationsbäume funktionieren vom Prinzip her fast gleich wie Regressionsbäume. Auch hier versuchen wir den Input Space (mit rechteckigen Formen) so zu segmentieren, dass die resultierenden Regionen die kategorische Outputvariable möglichst gut klassifizieren. Es gibt jedoch zwei zentrale Unterschiede im Vergleich zum Regressionsproblem:
Die Vorhersage in einer Region \(R_k\) entspricht nicht wie beim Regressionsbaum dem Mittelwert über die Outputvariable, sondern der am häufigsten vorkommenden Output-Kategorie in der Entscheidungsregion \(R_k\).
Der Trainingsalgorithmus minimiert nicht den MSE, sondern den Gini Index. Der Gini Index ist ein Mass für die “Reinheit” in einem Leaf Node. Warum ist das ein gutes Gütekriterium? Ein perfekter Baum hat in jedem Leaf Node nur noch Beobachtungen einer Kategorie. In dem Fall ist die “Reinheit” maximal. Schauen wir uns doch kurz die Formel für die Berechnung des Gini Indexes (für die \(k\)-te Entscheidungsregion \(R_k\)) an:
\[ G_k = \sum_{l=1}^L \hat{p}_{kl} \cdot (1-\hat{p}_{kl}) \] \(\hat{p}_{kl}\) beschreibt hier den Anteil der \(l\)-ten Output-Kategorie in der \(k\)-ten Entscheidungsregion \(R_k\). Die Gesamtkostenfunktion ist dann einfach die Summe über die Gini Indizes in den verschiedenen Regionen, also \(\sum_k G_k\).
Fragen
- Wir haben ein binäres Klassifikationsproblem und wollen vorhersagen, ob jemand zahlungsunfähig wird oder nicht. In einer Entscheidungsregion des Baums haben wir 20 Beobachtungen, davon 15, die nicht zahlungsunfähig werden. Was ist der Wert des Gini Indexes in dieser Region?
- Welchen Wert hat der Gini Index, wenn eine Entscheidungsregion nur noch Beobachtungen einer Kategorie enthält?
TippLösung
Die Lösung für die erste Frage rechnet sich wie folgt:
\[\begin{align} G_k &= \sum_{l=1}^L \hat{p}_{kl} \cdot (1-\hat{p}_{kl})\\ &= \frac{5}{20} \cdot \left(1-\frac{5}{20}\right) + \frac{15}{20} \cdot \left(1-\frac{15}{20}\right)\\ &= 2 \cdot \frac{5}{20} \cdot \frac{15}{20}\\ &= \frac{150}{400} = 0.375 \end{align}\]
Wenn eine Entscheidungsregion nur noch Beobachtungen einer Kategorie enthält, dann ist deren Anteil \(\hat{p}=1\). Daraus ergibt sich folgende Gini Index Berechnung: \(1 \cdot (1 - 1) + 0 \cdot (1 - 0) = 0\). Das ist auch gut so, denn wir wollen den Gini Index als eine Kostenfunktion interpretieren. Wir haben nur dann Kosten von 0, wenn eine Entscheidungsregion nur noch Beobachtungen einer Output-Kategorie enthält.
VorsichtEntropie (optional)
Eine Alternative zum Gini Index als Kostenfunktion ist die Entropie. Für die \(k\)-te Entscheidungsregion \(R_k\) rechnet sie sich wie folgt:
\[ H_k = - \sum_{l=1}^L \hat{p}_{kl} \cdot \log_2\,\left(\hat{p}_{kl}\right) \] Die Unterschiede zwischen dem Gini Index und Entropie als Kostenfunktion sind in der Praxis meist nicht von grosser Relevanz, aber es kann sich trotzdem lohnen, beide auszuprobieren und mittels Cross-Validation zu überprüfen, welche davon besser funktioniert.
Drei wichtige Punkte gilt es noch zu erwähnen:
- Wie bei der logistischen Regression gesehen (Kapitel 3), geben uns die meisten Klassifkationsmodelle eine Wahrscheinlichkeit zurück, dass die Outputvariable \(y_i\) der ersten Kategorie angehört (\(y_i=1\)). Das ist auch für Klassifikationsbäume möglich. Anstelle der am häufigsten vorkommenden Kategorie (hard prediction) können wir uns vom Baum auch die relativen Anteile der Kategorien in einer Entscheidungsregion (bzw. einem Leaf Node) ausgeben lassen (soft predictions). Diese Anteil können als Wahrscheinlichkeiten für die verschiedenen Kategorien interpretiert werden.
- Ein Klassifikationsbaum ist nicht auf eine binäre Outputvariablen limitiert und kann problemlos auf mehrklassige Outputvariablen angewendet werden.
- Kategoriale Input-Variablen sind übrigens auch problemlos in Bäumen verwendbar. Beispiel: wir haben eine Input-Variable Augenfarbe mit drei möglichen Kategorien “blau”, “grün” und “braun”. Der Trainingsalgorithmus testet in diesem Fall alle möglichen Splits, hier sind es folgende drei:
- “blau” vs. “grün” oder “braun”
- “grün” vs. “blau” oder “braun”
- “braun” vs. “blau” oder “grün”.
Schauen wir uns zum Schluss dieses Abschnitts an, wie ein Klassifikationsbaum unser Beispiel mit zwei Input-Variablen aus Kapitel 3 segmentiert. Ich habe hier das R-Package tree verwendet und das Argument minsize auf 10 gesetzt (d.h., ein interner Knoten darf nicht weniger als 10 Beobachtungen enthalten):
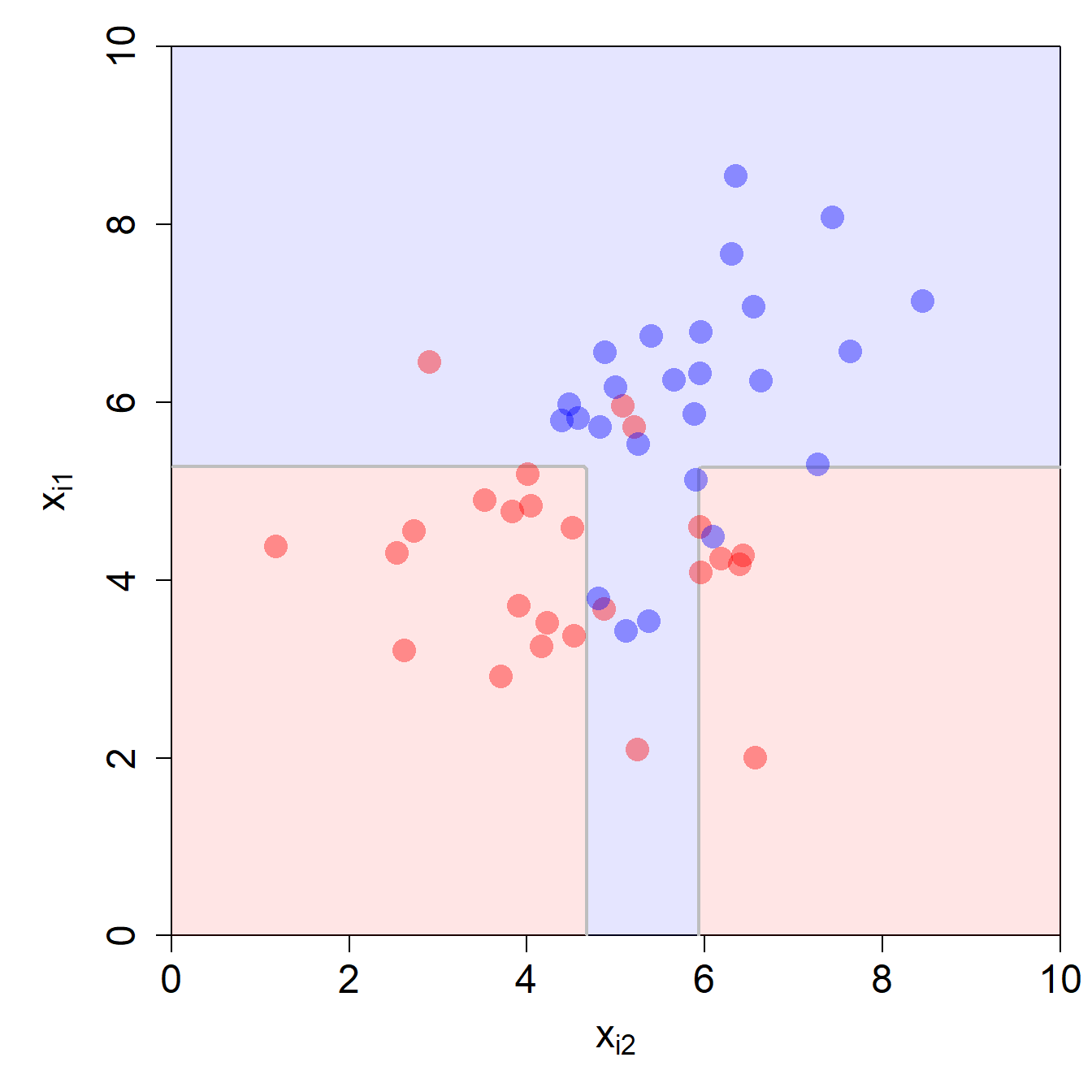
minsize = 10.Wir sehen hier auch gleich zwei Probleme von Bäumen:
- Die resultierende Decision Boundary ist viel zu kompliziert für dieses Beispiel (Overfitting).
- Die Decision Boundary ist begrenzt auf lineare Segmente, die in einem rechten Winkel zu den Achsen verlaufen. Das ist eine starke Limitierung dieses Modells.
Nachfolgend der gefittete Baum:
node), split, n, deviance, yval
* denotes terminal node
1) root 50 12.5000 0.5000
2) X1 < 5.25263 27 4.0740 0.1852
4) X2 < 4.66245 14 0.0000 0.0000 *
5) X2 > 4.66245 13 3.0770 0.3846
10) X2 < 5.92184 6 1.3330 0.6667 *
11) X2 > 5.92184 7 0.8571 0.1429 *
3) X1 > 5.25263 23 2.6090 0.8696
6) X2 < 5.22556 9 2.0000 0.6667 *
7) X2 > 5.22556 14 0.0000 1.0000 *Frage
Versuchen Sie den obigen R-Output gut zu verstehen. Sehen Sie die Splits im Input Space oben repräsentiert. Warum fehlt der Split repräsentiert durch 6) und 7)?
TippLösung
Der erste Split des Baums ist im R-Output durch 2) und 3) repräsentiert und bezieht sich auf die erste Input-Variable. Im Input Space entspricht der Split dem horizontalen Segment auf der Höhe 5.25.
Der zweite und dritte Split des Baums ist im R-Output durch 4) und 5) respektive 6) und 7) repräsentiert. Beide beziehen sich auf die zweite Input-Variable.
Der zweite Split ist im Input Space repräsentiert durch das vertikale Segment auf der Höhe 4.66 (im unteren, roten Teil des Input Space).
Der dritte Split ist im Input Space nicht repräsentiert. Warum nicht? Wenn Sie den Split in 6) und 7) genau anschauen, dann sehen Sie, dass in beiden Regionen der Anteil der blauen Beobachtungen über 0.5 liegt (0.67 und 1.0). Das bedeutet, dass dieser Split mit einem Threshold von 0.5 keinen Einfluss auf die Decision Boundary hat.
Der vierte Split des Baums ist im R-Output durch 10) und 11) repräsentiert und bezieht sich auf die zweite Input-Variable. Im Input Space entspricht der Split dem vertikalen Segment auf der Höhe 5.92.
5.3 Entscheidungsbäume in R
Wir illustrieren die Anwendung von Entscheidungsbäumen anhand des Heart Datensatzes, der auch in (James u. a. 2021, Kap. 8) verwendet wird und sich sehr gut eignet. Der ursprüngliche Datensatz kann vom UC Irvine ML Repository heruntergeladen werden. Eine vorverarbeitete Version des Datensatzes, die wir unten verwenden, kann hier heruntergeladen werden.
Der Datensatz enthält diverse Angaben zu 303 Patientinnen und Patienten, die mit Herzproblemen in ein Spital eingeliefert wurden. Unser Ziel ist es, aufgrund von verschiedenen Attributen vorherzusagen, ob eine Patientin oder ein Patient eine Herzerkrankung hat.
Der Datensatz umfasst folgende Variablen:
age: Altersex: Geschlechtcp: Art der Brustkorbschmerzen, 4 Kategorientrestbps: systolischer Blutdruckchol: Cholesterin-Wert im Blutfbs: Blutzuckerwert (gemessen am Morgen auf nüchternen Magen) grösser als 120 mg/dl? (yes / no)restecg: EKG Resultate, 3 Kategorienthalach: Maximale erreichte Herzfrequenzexang: Durch Sport ausgelöstes Angina (reduzierte Blutzufuhr zum Herz)? (yes / no)oldpeak: Parameter der EKG Messungslope: Parameter der EKG Messung, 3 Kategorienca: Anzahl Hauptarterienthal: Thallium Stress Test Resultate (wie gut fliesst Blut zum Herz?), 3 Kategorienhd: Herzerkrankung? (yes / no) - Outputvariable
Laden wir als erstes die nötigen R-Packages.
library(rpart.plot)
library(tidyverse)
library(tidymodels)Als nächstes überprüfen wir kurz, ob der Dataframe fehlende Werte enthält:
# Fehlende Werte?
sapply(heart, function(x) sum(is.na(x))) age sex cp trestbps chol fbs restecg thalach
0 0 0 0 0 0 0 0
exang oldpeak slope ca thal hd
0 0 0 4 2 0 Wir sehen, dass die Variable ca 4 fehlende Werte und die Variable thal zwei fehlende Werte enthält. Ein weiterer Vorteil von Entscheidungsbäumen ist, dass sie gut mit fehlenden Werten umgehen können. Was effektiv passiert, ist folgendes: wenn in einem Split eine Variable verwendet wird, welche fehlende Werte enthält, dann wird für die Beobachtungen mit fehlenden Werten eine andere Variable (sogenanntes Surrogat) für den Split verwendet, welche möglichst ähnliche Entscheidungen trifft wie die eigentliche Splitvariable.
Als nächstes stellen wir sicher, dass wir keine starke Imbalance in der Outputvariable haben:
# Ist der Datensatz balanced?
heart |>
count(hd) |>
mutate(prop = n / sum(n)) hd n prop
1 no 164 0.5412541
2 yes 139 0.4587459Das sieht gut aus. Ein Verhältnis von 54% Nein (keine Herzerkrankungen) zu 46% Ja (Herzerkrankungen) in der Outputvariable ist akzeptabel.
Wir machen hier ausnahmsweise keinen Train-Test Split, da es hier lediglich darum geht, die Anwendung von Entscheidungsbäumen zu demonstrieren. In einem richtigen ML-Projekt würden wir allerdings spätestens hier einen Train-Test Split vollziehen.
Stattdessen erstellen wir 5 Folds, um die optimalen Hyperparameter mit 5-Fold Cross-Validation zu finden.
# Seed für Reproduzierbarkeit
set.seed(123)
# 5-Fold CV
folds <- vfold_cv(heart, v = 5, repeats = 1, strata = hd)Nun spezifizieren wir das Modell mit der Funktion decision_tree() aus tidymodels. Wir werden hier die Hyperparameter tree_depth (Tiefe des Baums) und min_n (minimale Anzahl Beobachtungen in einem Node) tunen. Den Hyperparameter cost_complexity setzen wir auf 0 (diesen würden wir für das Pruning eines Baums verwenden). Wir spezifizieren ausserdem, dass es sich um ein Klassifikationsproblem handelt und dass wir das R-Package rpart für das Fitting verwenden wollen.
# Spezifikation des Classification Trees
dt_mod <-
decision_tree(tree_depth = tune(), min_n = tune(), cost_complexity = 0) |>
set_mode("classification") |>
set_engine("rpart")Im Workflow definieren wir unter anderem die Modellgleichung hd ~ ., d.h. die Variable hd ist die Outputvariable und alle anderen werden als Input-Variablen verwendet.
# Workflow
dt_workflow <-
workflow() |>
add_model(dt_mod) |>
add_formula(hd ~ .)Wir erstellen einen Tuning Grid für die beiden Hyperparameter, die wir tunen wollen:
# Tuning Grid
dt_grid <- expand.grid(tree_depth = seq(1, 10, by = 2), min_n = seq(10, 30, 5))
# Wie sieht Grid aus?
print(dt_grid) tree_depth min_n
1 1 10
2 3 10
3 5 10
4 7 10
5 9 10
6 1 15
7 3 15
8 5 15
9 7 15
10 9 15
11 1 20
12 3 20
13 5 20
14 7 20
15 9 20
16 1 25
17 3 25
18 5 25
19 7 25
20 9 25
21 1 30
22 3 30
23 5 30
24 7 30
25 9 30Nun sind wir bereit, das Modell zu fitten und das Hyperparameter Tuning durchzuführen. Wir verwenden sowohl die Fläche unter der ROC-Kurve als auch die Accuracy, um die Modellgüte zu messen:
# Tuning / Model Fitting
dt_res <-
dt_workflow |>
tune_grid(
resamples = folds,
grid = dt_grid,
control = control_grid(save_pred = TRUE, save_workflow = TRUE),
metrics = metric_set(roc_auc, accuracy))Schauen wir uns doch die besten 10 Hyperparameter Werte gemäss ROC AUC Kriterium an:
# Wir sortieren die Hyperparameter Spezifikationen nach ROC AUC
dt_res |>
show_best(metric = "roc_auc", n = 10) |>
arrange(desc(mean))# A tibble: 10 × 8
tree_depth min_n .metric .estimator mean n std_err .config
<dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 5 20 roc_auc binary 0.824 5 0.0223 pre0_mod13_post0
2 7 20 roc_auc binary 0.824 5 0.0223 pre0_mod18_post0
3 9 20 roc_auc binary 0.824 5 0.0223 pre0_mod23_post0
4 3 20 roc_auc binary 0.815 5 0.0191 pre0_mod08_post0
5 3 25 roc_auc binary 0.815 5 0.0191 pre0_mod09_post0
6 3 30 roc_auc binary 0.815 5 0.0191 pre0_mod10_post0
7 7 15 roc_auc binary 0.813 5 0.0281 pre0_mod17_post0
8 9 15 roc_auc binary 0.813 5 0.0281 pre0_mod22_post0
9 3 10 roc_auc binary 0.812 5 0.0241 pre0_mod06_post0
10 3 15 roc_auc binary 0.812 5 0.0241 pre0_mod07_post0Nun fitten wir den optimalen Decision Tree (tree_depth = 5 und min_n = 20) auf dem ganzen Datensatz, so dass wir den letzten optimalen Fit kriegen:
# Last Fit (auf ganzem Trainingsdatensatz)
last_dt_fit <- fit_best(dt_res)Wir können uns den Last Fit mal ausgeben lassen:
# Last Fit
last_dt_fit══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Formula
Model: decision_tree()
── Preprocessor ────────────────────────────────────────────────────────────────
hd ~ .
── Model ───────────────────────────────────────────────────────────────────────
n= 303
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 303 139 no (0.54125413 0.45874587)
2) thal=normal 167 38 no (0.77245509 0.22754491)
4) cp=atypical angina,non-anginal pain 100 9 no (0.91000000 0.09000000) *
5) cp=typical angina,asymptomatic 67 29 no (0.56716418 0.43283582)
10) ca< 0.5 40 9 no (0.77500000 0.22500000)
20) age< 51.5 15 0 no (1.00000000 0.00000000) *
21) age>=51.5 25 9 no (0.64000000 0.36000000)
42) exang=no 17 4 no (0.76470588 0.23529412) *
43) exang=yes 8 3 yes (0.37500000 0.62500000) *
11) ca>=0.5 27 7 yes (0.25925926 0.74074074)
22) sex=female 7 3 no (0.57142857 0.42857143) *
23) sex=male 20 3 yes (0.15000000 0.85000000) *
3) thal=fixed defect,reversable defect 136 35 yes (0.25735294 0.74264706)
6) cp=typical angina,atypical angina,non-anginal pain 46 21 no (0.54347826 0.45652174)
12) ca< 0.5 29 8 no (0.72413793 0.27586207)
24) oldpeak< 0.1 7 0 no (1.00000000 0.00000000) *
25) oldpeak>=0.1 22 8 no (0.63636364 0.36363636)
50) chol< 259.5 13 3 no (0.76923077 0.23076923) *
51) chol>=259.5 9 4 yes (0.44444444 0.55555556) *
13) ca>=0.5 17 4 yes (0.23529412 0.76470588) *
7) cp=asymptomatic 90 10 yes (0.11111111 0.88888889)
14) oldpeak< 0.55 22 8 yes (0.36363636 0.63636364)
28) chol< 237.5 12 5 no (0.58333333 0.41666667) *
29) chol>=237.5 10 1 yes (0.10000000 0.90000000) *
15) oldpeak>=0.55 68 2 yes (0.02941176 0.97058824) *Hmm, etwas schwierig da den Überblick zu behalten. Mithilfe des R-Packages rpart.plot können wir den finalen Baum plotten, so dass er einfacher lesbar wird:
# Plot des finalen Baums
last_dt_fit |>
extract_fit_engine() |>
rpart.plot()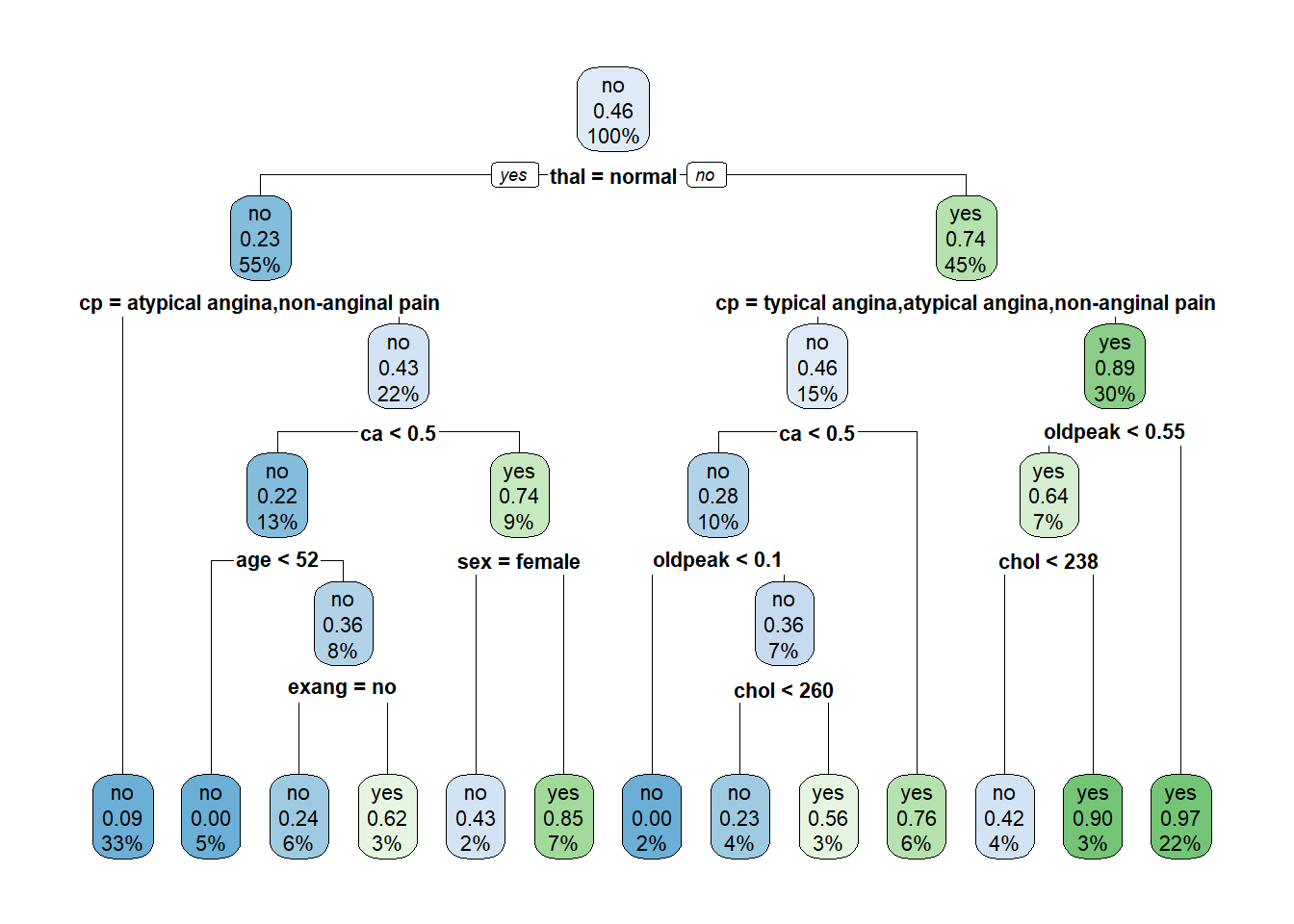
Jeder Knoten im Baum enthält drei Informationen: erstens die Vorhersage, die der Baum in diesem Knoten machen würde, zweitens den relativen Anteil an Beobachtungen mit Herzerkrankung und drittens den gesamten relativen Anteil von Beobachtungen, welche in diesem Knoten landen. Anhand der Anzahl Leaf Nodes sehen wir, dass dieser Baum den Input Space in 13 Entscheidungsregionen aufteilt.
Nun plotten wir noch die ROC-Kurve für das finale Modell:
# ROC Kurve für finalen Baum
dt_auc <-augment(last_dt_fit, new_data = heart) |>
roc_curve(hd, .pred_yes, event_level = "second")
# ROC Kurve
autoplot(dt_auc)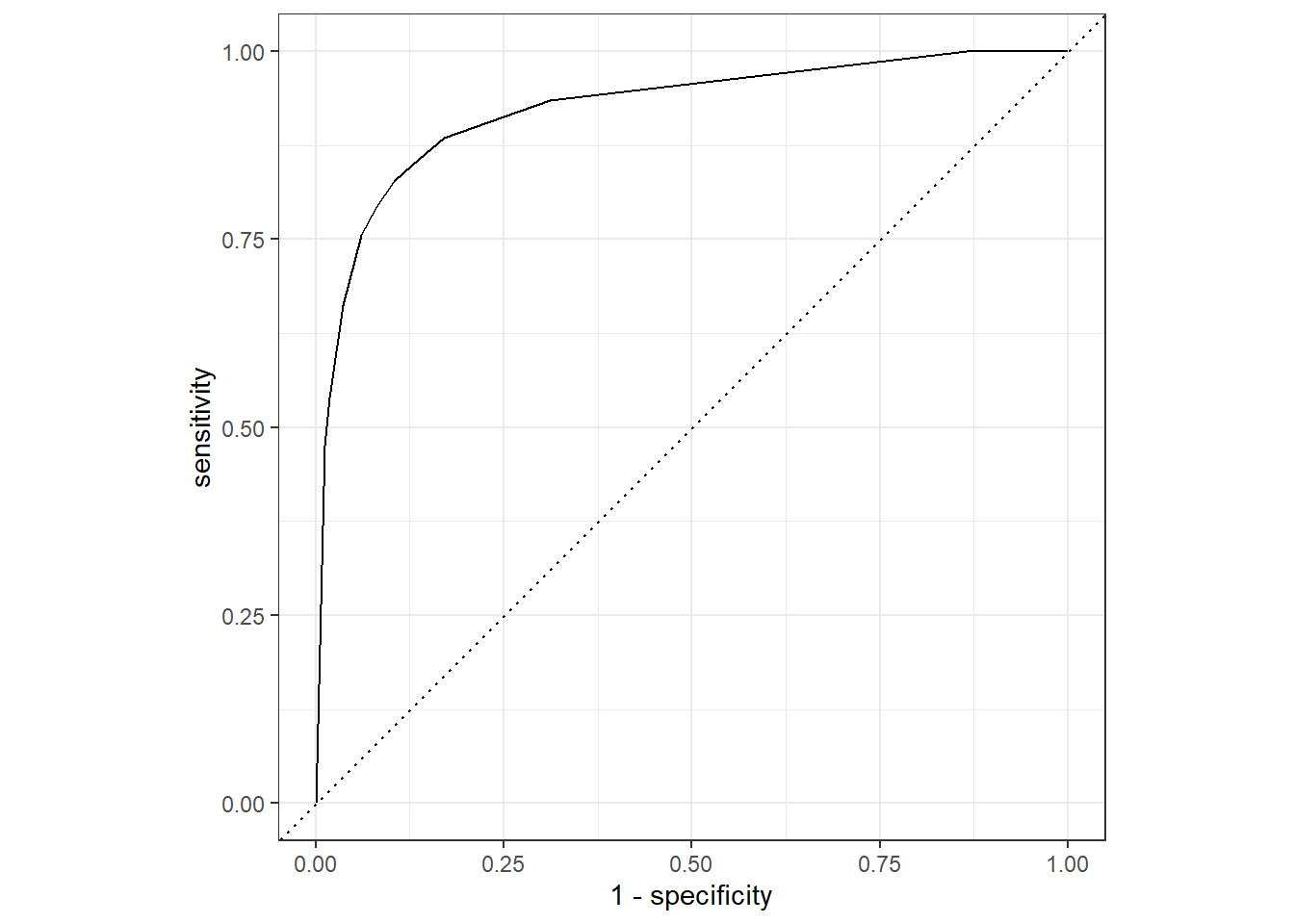
Mithilfe der Funktion predict() können wir basierend auf dem finalen Baum Vorhersagen für neue Beobachtungen machen. Hier tun wir das der Einfachheit halber für die fünfte Beobachtung im Datensatz heart. Wichtig: mit type = "class" kriegen wir eine hard prediction für die Beobachtung, während wir mit type = "prob" die soft prediction kriegen, also die Anteile von “yes” und “no” im Leaf Node (bzw. der Entscheidungsregion), in dem die fünfte Beobachtung landet.
# Vorhersagen
predict(last_dt_fit, new_data = heart[5, ], type = "class")# A tibble: 1 × 1
.pred_class
<fct>
1 no predict(last_dt_fit, new_data = heart[5, ], type = "prob")# A tibble: 1 × 2
.pred_no .pred_yes
<dbl> <dbl>
1 0.91 0.09Wir sind uns bei dieser Person ziemlich sicher, dass keine Herzerkrankung vorliegt.