3 Lineare Klassifikation
Nachdem wir uns in Kapitel 2 bereits ausführlich mit dem Regressionsproblem befasst haben, lernen wir hier nun das andere grosse Supervised Learning Problem kennen: das Klassifikationsproblem. In der Praxis sind Klassifikationsprobleme fast häufiger anzutreffen als Regressionsprobleme.
Wir fokussieren hier erstmal auf das binäre Klassifikationsproblem, bei dem unser Ziel ist vorherzusagen, ob eine Beobachtung der Kategorie 1 (\(y_i=1\)) oder der Kategorie 0 (\(y_i=0\)) angehört.1 Unsere Output-Variable ist hier also nicht mehr quantitativer Natur, sondern qualitativ (d.h. kategorisch) und hat zwei mögliche Kategorien (oder Klassen).
Wir werden uns in diesem Kapitel drei Modelle für das Klassifikationsproblem anschauen:
- Logistische Regression2 (LR)
- Naive Bayes (NB)
- K-Nearest Neighbors (KNN)
Wichtig: der Titel des Kapitels besagt, dass wir uns lineare Klassifikationsmodelle anschauen. Das stimmt nicht ganz, denn während das logistische Regressionsmodell und (unter gewissen Bedingungen) Naive Bayes lineare Modelle sind, ist KNN ein sehr flexibles, nicht-lineares Modell.
3.1 Logistische Regression
Die logistische Regression ist das Gegenstück zur linearen Regression für das Klassifikationsproblem. Es ist ein einfaches Modell, das oft als guter Ausgangspunkt für jegliche Klassifikationsprobleme dient. Das heisst, es macht meist Sinn, als erstes Modell ein logistisches Regressionsmodell zu trainieren.
3.1.1 Output-Variable
Die Output-Variable bzw. das Label im binären Klassifikationsproblem ist eine kategorische Variable mit zwei möglichen Kategorien (oder Klassen). Wie oben erwähnt nimmt die Output-Variable den Wert 1 an, also \(y_i=1\), falls eine Beobachtung der Kategorie 1 angehört und sonst den Wert 0, also \(y_i=0\). Typischerweise geben wir den Wert 1 der Kategorie, die uns wirklich interessiert (z.B. Spam, Zahlungsunfähigkeit, Patient hat eine Krankheit).
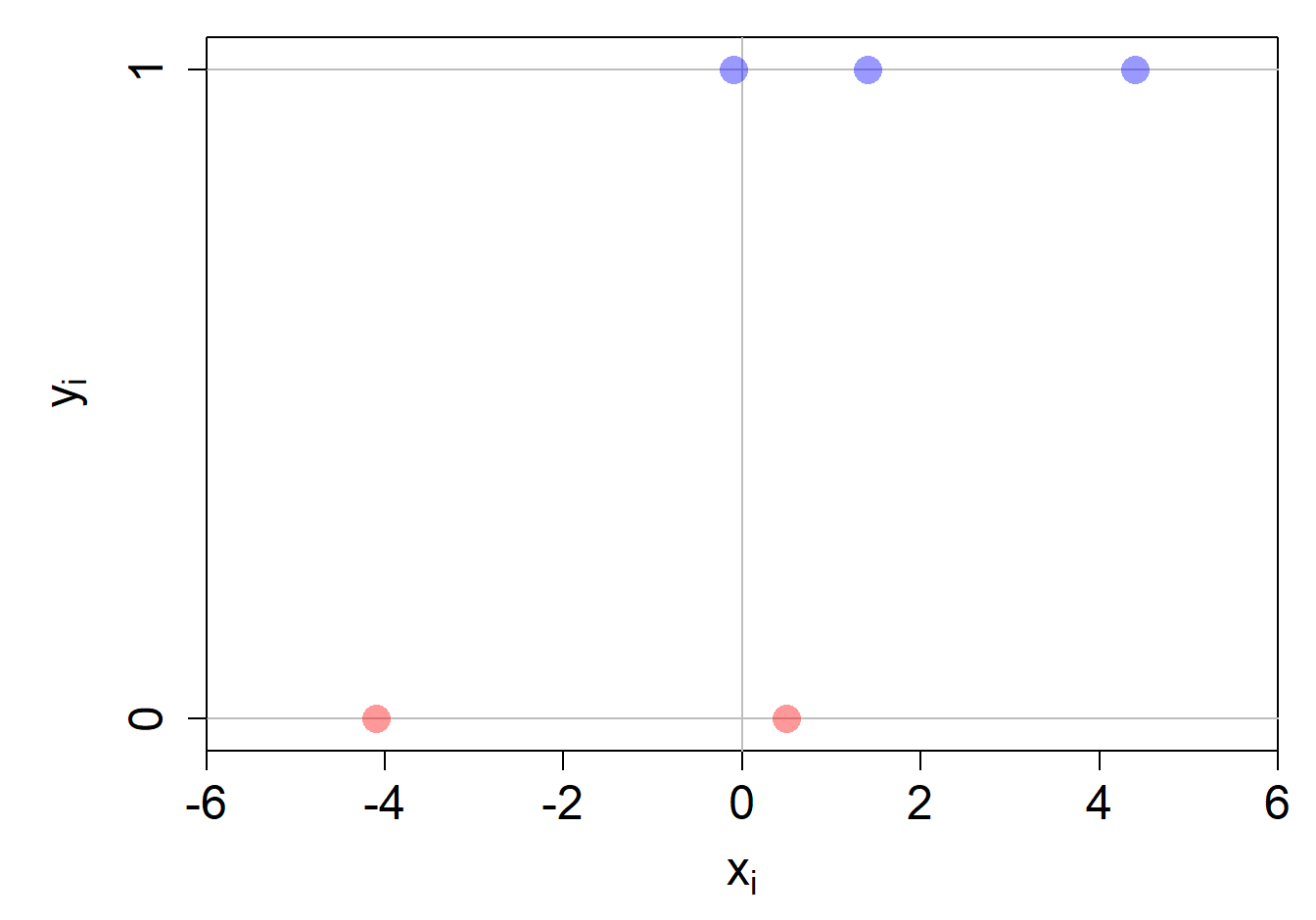
In folgender Abbildung ist ein Klassifikationsproblem mit 5 Beobachtungen dargestellt. Die drei blauen Datenpunkte gehören der Kategorie 1 an, während die zwei roten Datenpunkte der Kategorie 0 angehören. Wir werden weiter unten auf dieses Problem zurückkommen.
Bei den meisten Klassifikationsmodellen wird nicht direkt der Output \(y_i\) modelliert (wie das bei den Regressionsproblemen der Fall ist), sondern die (bedingte) Wahrscheinlichkeit, dass \(y_i=1\), gegeben irgendwelche Input-Datenwerte.3 Mathematisch schreiben wir diese Wahrscheinlichkeit als \(p(y_i = 1 \mid \mathbf{x}_i)\). Alle unsere Modelle hier werden versuchen, möglichst genaue Schätzung für diese bedingte Wahrscheinlichkeit zu finden.
Frage
Warum modellieren wir \(p(y_i = 1 \mid \mathbf{x}_i)\) nicht mit dem linearen Regressionsmodell?
- Je nach Input-Daten könnten wir negative Outputs (d.h. Wahrscheinlichkeiten) oder Outputs grösser als 1 erhalten.
- Weil wir für die Klassifikation nie ein lineares Modell schätzen.
- Das lineare Regressionsmodell funktioniert gar nicht in diesem Fall.
TippLösung
Die richtige Antwort ist a.
Antwort b. stimmt nicht, weil es sich beim logistischen Regressionsmodell ja eben auch um ein lineares Modell handelt.
Antwort c. stimmt nicht, weil das lineare Regressionsmodell technisch problemlos rechenbar ist, aber eben zum unerwünschten Resultat (beschrieben in a.) führt.
Nun wundern Sie sich vielleicht: wenn uns unser Modell eine Schätzung für \(p(y_i = 1 \mid \mathbf{x}_i)\) zurück gibt, wie mache ich damit eine Vorhersage?
Im einfachsten Fall ist unsere Vorhersage \(\hat{y}_i=1\) (also Kategorie 1), falls die geschätzte Wahrscheinlichkeit \(p(y_i = 1 \mid \mathbf{x}_i) > 50\%\), und sonst \(\hat{y}_i=0\). Hier haben wir einen Threshold von 50% gewählt, aber grundsätzlich können wir auch andere Thresholds wählen (z.B. 20% oder 85%), um von den geschätzten Wahrscheinlichkeiten eine Vorhersage abzuleiten. Wir werden uns in Kapitel 4 genauer mit dem optimalen Threshold befassen.
3.1.2 Modellspezifikation
Bevor wir das logistische Regressionsmodell spezifizieren, erinnern wir uns ganz kurz an die Modellspezifikation des linearen Regressionsmodells:
\[ f(\mathbf{x}_i) = w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip} \] Diese gewichtete Summe der Input-Variablenwerte wird auch bei der logistischen Regression eine wichtige Rolle spielen. Wir haben in der ersten Frage zu diesem Kapitel bereits gesehen, dass folgende Modellgleichung leider nicht eine gute Idee ist:
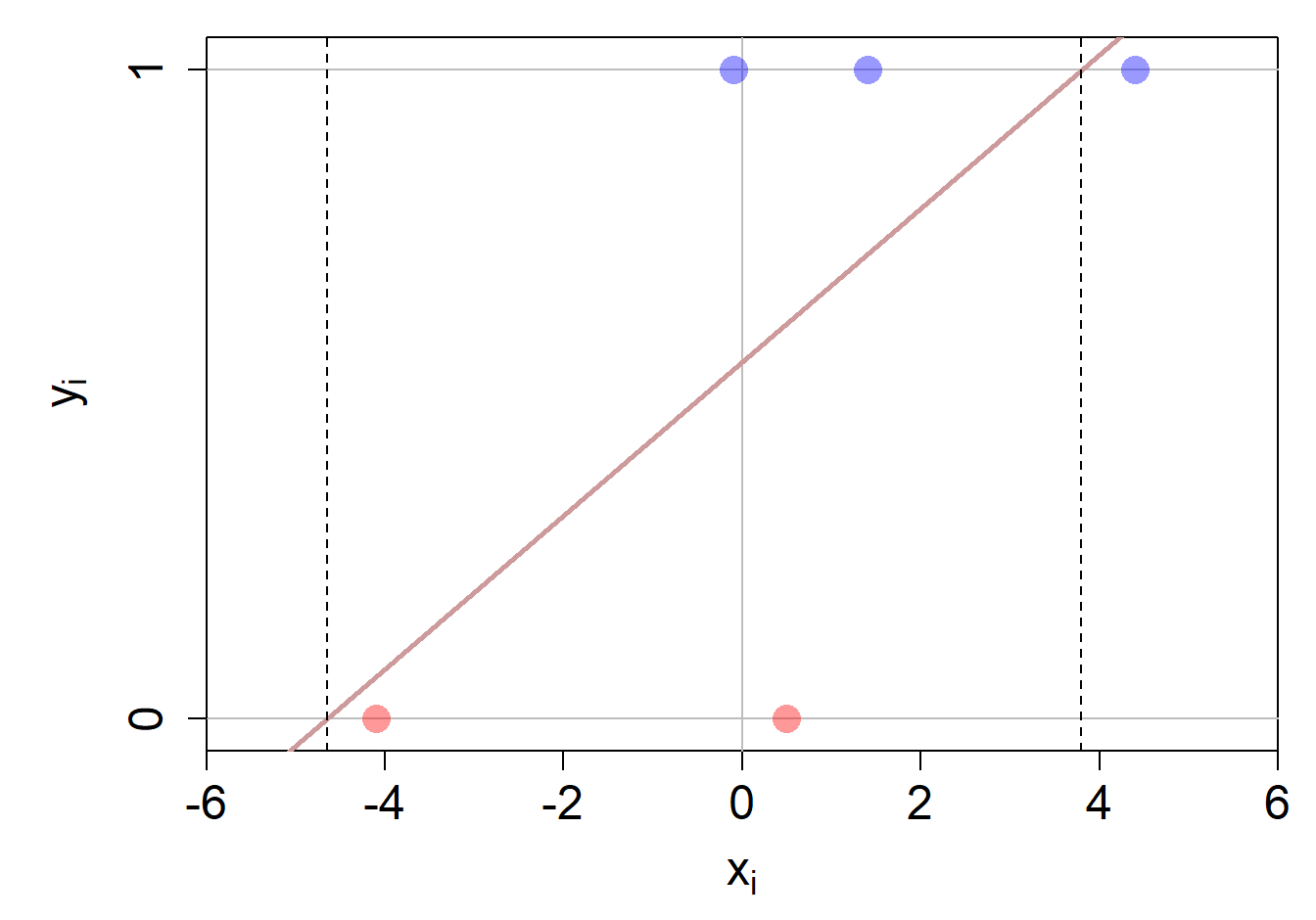
\[ p(y_i = 1 \mid \mathbf{x}_i) = w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip} \] Warum nicht? Weil die gewichtete Summe je nach Input-Daten mal negativ sein kann oder auch grösser als 1. Gleichzeitig wissen wir aus der Wahrscheinlichkeitstheorie, dass eine Wahrscheinlichkeit immer zwischen 0 und 1 liegen muss. Folgende Abbildung zeigt, dass das lineare Regressionsmodell nur innerhalb der gestrichelten, vertikalen Linien eine Wahrscheinlichkeit zwischen 0 und 1 zurück gibt.
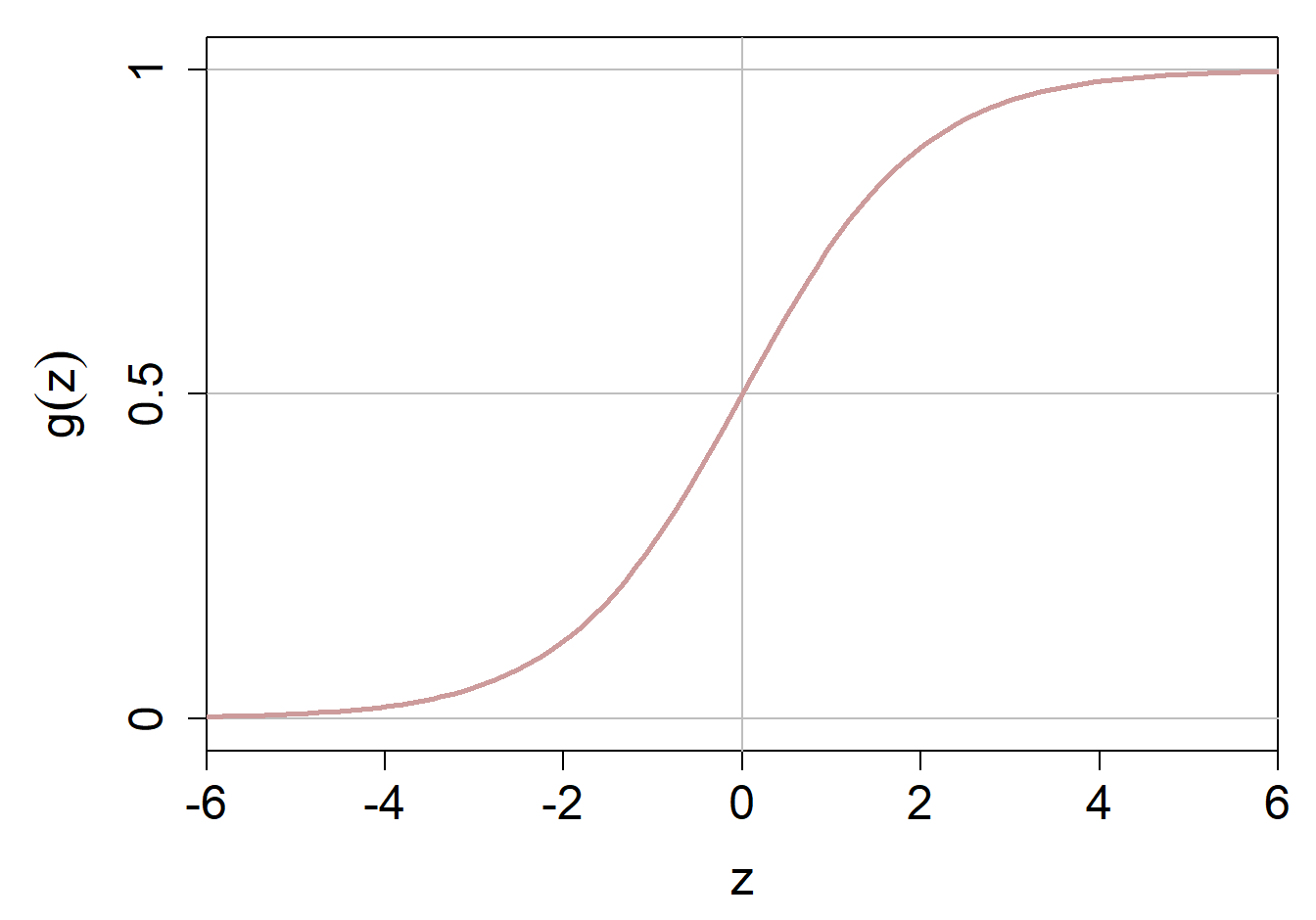
Wir müssen also die gewichtete Summe in eine mathematische Funktion “verpacken”, so dass die Outputs dieser Funktion immer zwischen 0 und 1 liegen und dementsprechend die Definition einer Wahrscheinlichkeit erfüllen. Die Sigmoid Funktion (auch logistische Funktion genannt) tut genau das. Sie nimmt irgendeinen (reellen) Input \(z\) und gibt immer einen Wert zwischen 0 und 1 zurück. Die Funktion sieht folgendermassen aus:
\[ g(z) = \frac{e^z}{1+e^z}=\frac{1}{1+e^{-z}} \]
VorsichtZwei Formen der Sigmoid Funktion (optional)
Wir wollen uns hier anschauen, wie wir von der einen zur anderen Form der Sigmoid Funktion kommen:
\[ \frac{e^z}{1+e^z} \cdot \frac{e^{-z}}{e^{-z}} = \frac{e^z \cdot e^{-z}}{(1+e^z) \cdot e^{-z}} = \frac{e^0}{e^{-z} + e^0} = \frac{1}{1+e^{-z}} \] Wir multiplizieren die erste Form der Sigmoid Funktion in einem ersten Schritt mit \(\frac{e^{-z}}{e^{-z}}\). Das ist erlaubt, weil dieser Ausdruck ja nichts anderes als 1 ist und durch diese Multiplikation die Sigmoid Funktion nicht verändert wird. Der Rest ist dann einfaches, algebraisches Umformen.
Für jeden Wert von \(z\) gibt uns die Funktion \(g(z)\) einen Wert zwischen 0 und 1 zurück. Grafisch sieht die Sigmoid Funktion folgendermassen aus:
Frage
Was ist der Output der Sigmoid Funktion, wenn \(z=2.6\)?
TippLösung
Die korrekte Antwort ist 0.9309.
Nun können wir alles zusammensetzen, was ganz einfach bedeutet, dass wir nun anstelle von \(z\) die gewichtete Summe der Input-Variablen in die Sigmoid Funktion einsetzen. Das logistische Regressionsmodell sieht dementsprechend dann wie folgt aus:
\[\begin{align} p(y_i = 1 \mid \mathbf{x}_i) &= \frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}\\ &= \frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}} \end{align}\]
Im nächsten Abschnitt wollen wir herausfinden, wie die Parameter des Modells geschätzt werden.
3.1.3 Modelltraining
Modelltraining bedeutet auch hier nichts anderes, als dass wir die Parameter des Modells möglichst optimal schätzen wollen. Sie haben in Kapitel 2 (Perspektive 1 des Modelltrainings bei der linearen Regression) bereits gelernt, dass wir in der Phase des Modelltrainings eine Kostenfunktion aufstellen, die es dann zu minimieren gilt. Doch wie soll eine Kostenfunktion für das Klassifikationsproblem aussehen?
Im Idealfall gibt unser Modell eine Wahrscheinlichkeit von 0 aus für alle Beobachtungen, bei denen \(y_i=0\), während für alle Beobachtungen, wo \(y_i=1\), eine Wahrscheinlichkeit von 1 zurückgegeben wird. In diesem Idealfall sollte die Kostenfunktion 0 betragen. Wie können wir das mathematisch abbilden?
Die “Kosten” für eine einzelne Beobachtung mit dem (wahren) Outputwert \(y_i=1\) schreiben wir als \(-\text{log}(p(y_i = 1 \mid \mathbf{x}_i))\). Für Beobachtungen mit dem (wahren) Label \(y_i=0\) sind die “Kosten” dementsprechend \(-\text{log}(1-p(y_i = 1 \mid \mathbf{x}_i))\). Warum das Sinn macht, sehen Sie anhand folgender Abbildung:
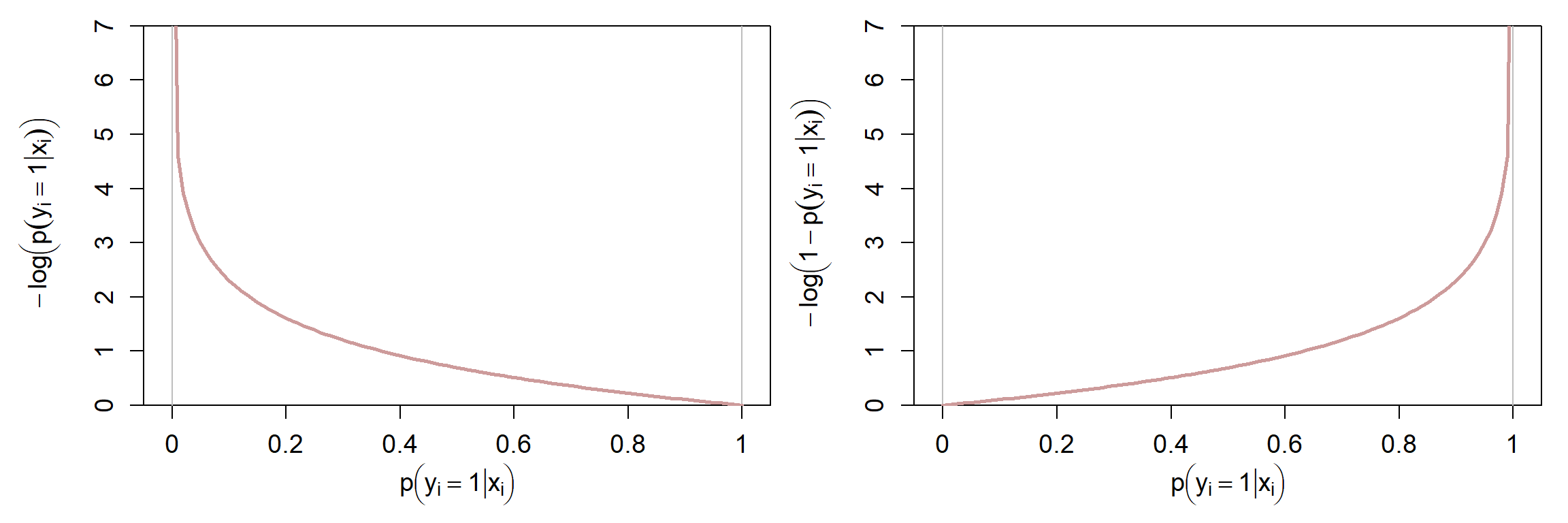
In der linken Abbildung sehen Sie einen Kostenwert, der immer kleiner wird, je grösser die Wahrscheinlichkeit \(p(y_i = 1 \mid \mathbf{x}_i)\). Rechts sehen wir genau das Gegenteil: je grösser diese Wahrscheinlichkeit, desto grösser die Kosten. Wir wollen in diesem Fall, dass die Wahrscheinlichkeit \(p(y_i = 1 \mid \mathbf{x}_i)\) so klein wie möglich ist.
Wir haben nun die Kosten für einzelne Beobachtungen angeschaut und gesehen, dass die Kosten je nach wahrem Label \(y_i\) unterschiedlich sind. Die Gesamtkostenfunktion ist der Durchschnitt über die individuellen Kosten (gemittelt über alle Beobachtungen im Trainingsdatensatz). Mathematisch sieht das Ganze folgendermassen aus:
\[ J = -\frac{1}{n}\sum_{i=1}^n \left[y_i \cdot \log\left(p(y_i = 1 \mid \mathbf{x}_i)\right) + (1-y_i) \cdot \log\left(1-p(y_i = 1 \mid \mathbf{x}_i)\right)\right] \]
Überlegen Sie sich kurz, warum diese Berechnung Sinn macht. Wenn die \(i\)-te Beobachtung das Label \(y_i=1\) hat, dann entfällt der zweite Teil in den eckigen Klammern, weil in diesem Fall \((1-y_i)=0\) ist. Wenn die \(i\)-te Beobachtung hingegen das Label \(y_i=0\) hat, dann entfällt der erste Teil in den eckigen Klammern, weil die individuellen Kosten mit 0 multipliziert werden. Wir haben hier also eine kompakte mathematische Form, um die Gesamtkostenfunktion aufzuschreiben. In der Praxis wird diese Kostenfunktion häufig log-loss genannt.
Wir suchen also nun die Parameterwerte \(w_0, w_1, \dots\), welche die obige Kostenfunktion minimieren. Leider gibt es keine analytische Lösung dafür. Wir können aber die optimalen Parameterwerte mit anderen (iterativen) Optimierungsmethoden finden. In R und Python sind diese Methoden effizient implementert (Abschnitt 3.4), so dass wir die Parameter, welche diese Kostenfunktion minimieren, oft in wenigen Millisekunden finden.
Die folgende Abbildung zeigt das trainierte Modell:
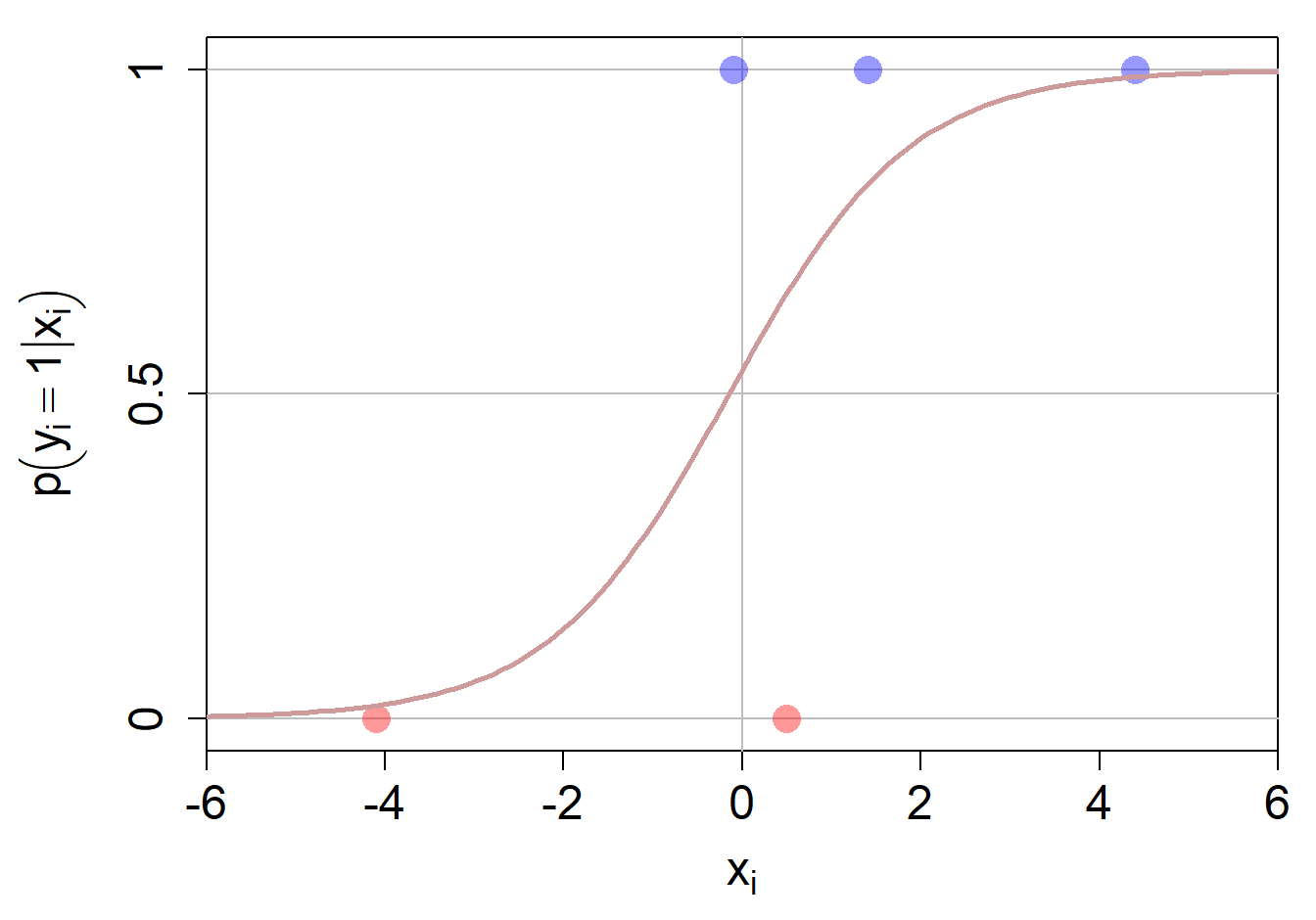
Die optimalen Parameterwerte sind \(w_0 = 0.15\) und \(w_1 = 0.99\). Wir sehen, dass die gefittete Sigmoid Funktion nicht bei \(x_i=0\) den Wert 0.5 hat, sondern etwas vorher (nämlich bei -0.15).4 Unser finales Modell sieht also wie folgt aus:
\[ p(y_i = 1 \mid x_i) = \frac{1}{1+e^{-(0.15 + 0.99 \cdot x_{i})}} \]
Frage
Was ist die Vorhersage unseres Modells für den Input-Variablenwert \(x_i=-2\)?
TippLösung
Die korrekte Antwort ergibt sich durch Einsetzen des Werts in das trainierte Modell:
\[ p(y_i = 1 \mid x_i) = \frac{1}{1+e^{-(0.15 + 0.99 \cdot (-2))}} = \frac{1}{1+e^{-(-1.83)}} = 0.14 \] Gemäss unserem Modell ist die Wahrscheinlichkeit, dass \(y_i = 1\) lediglich 14% für diesen Input-Variablenwert.
Zwei letzte wichtige Punkte in diesem Abschnitt:
- Wie bei der linearen Regression verwenden wir bei der logistischen Regression typischerweise Regularisierung, um dem Overfitting entgegenzuwirken. Von der Idee her funktioniert es genau gleich wie bei der linearen Regression.
- Die durchschnittliche Wahrscheinlichkeit, welche unser trainiertes Modell auf dem Trainingsdatensatz schätzt, entspricht bei der logistischen Regression jeweils genau dem Anteil an Beobachtungen (im Trainingsdatensatz) mit Label \(y_i=1\).
VorsichtHerleitung des zweiten Punkts (optional)
Wir können das logistische Regressionsmodell schreiben als
\[ p(y_i = 1 \mid x_i) = g(\mathbf{w}' \mathbf{x_i})\,, \] wobei \(g()\) die Sigmoid Funktion bezeichnet.
Die erste Ableitung der allgemeinen Form der Sigmoid Funktion \(g(z)\) hat folgende einfache Form:
\[ \frac{d\,g(z)}{dz} = g(z) \cdot (1 - g(z)) \]
Nun können wir die Ableitung der Kostenfunktion nach den Modellparameter \(\mathbf{w}\) rechnen. Dazu verwenden wir die obigen zwei Resultate, die Tatsache, dass die Ableitung der Logarithmusfunktion \(\log(z)=\frac{1}{z}\) ist und die bekannte Kettenregel für Ableitungen:
\[ \begin{split} \frac{\partial J}{\partial \mathbf{w}} &= -\frac{1}{n} \sum_{i=1}^n \Bigl[ y_i \cdot \frac{1}{g(\mathbf{w}' \mathbf{x_i})} \cdot g(\mathbf{w}' \mathbf{x_i}) \cdot (1 - g(\mathbf{w}' \mathbf{x_i})) \cdot \mathbf{x}_i \\ &\qquad + (1- y_i) \cdot \frac{1}{1 - g(\mathbf{w}' \mathbf{x_i})} \cdot (-1) \cdot g(\mathbf{w}' \mathbf{x_i}) \cdot (1 - g(\mathbf{w}' \mathbf{x_i})) \cdot \mathbf{x}_i \Bigr] \\ &= -\frac{1}{n} \sum_{i=1}^n \left[y_i \cdot (1 - g(\mathbf{w}' \mathbf{x_i})) \cdot \mathbf{x}_i - (1- y_i) \cdot g(\mathbf{w}' \mathbf{x_i}) \cdot \mathbf{x}_i\right]\\ &= -\frac{1}{n} \sum_{i=1}^n \left[y_i \cdot \mathbf{x}_i - y_i \cdot \mathbf{x}_i \cdot g(\mathbf{w}' \mathbf{x_i}) - \mathbf{x}_i \cdot g(\mathbf{w}' \mathbf{x_i}) + y_i \cdot \mathbf{x}_i \cdot g(\mathbf{w}' \mathbf{x_i})\right]\\ &= -\frac{1}{n} \sum_{i=1}^n \left[y_i \cdot \mathbf{x}_i - \mathbf{x}_i \cdot g(\mathbf{w}' \mathbf{x_i})\right]\\ &= -\frac{1}{n} \sum_{i=1}^n \left[(y_i - g(\mathbf{w}' \mathbf{x_i})) \cdot \mathbf{x}_i\right]\\ \end{split} \] Obschon obige Umformung der Ableitung etwas wild daherkommt, sehen Sie vielleicht, dass wir mit simplen algebraischen Umformungen zu einem einfachen Ausdruck der ersten Ableitung in der letzten Zeile kommen.
Wir sehen nun folgende Elemente in dieser Ableitung:
- Der Term \((y_i - g(\mathbf{w}' \mathbf{x_i}))\) ist nichts anderes als eine Zahl (= Skalar), die den Fehler für die \(i\)-te Beobachtung beschreibt. Wie stark weicht die Vorhersage des Modells \(g(\mathbf{w}' \mathbf{x_i})\) vom wahren Output \(y_i\) ab?
- \(\mathbf{x_i}\) hingegen ist ein Vektor, weshalb die Ableitung oben im Prinzip die Ableitungen nach allen \(p\) Modellparameter enthält.
Aus letzterem Punkt folgt, dass wenn wir nun die Ableitung gleich Null setzen, um die optimalen Parameter zu finden, wir eigentlich ein Gleichungssystem mit \(p\) Gleichungen haben. Wir schauen uns hier nun aber nur die Ableitung nach der Konstante \(w_0\) an, für die \(\mathbf{x}_i\) an erster Stelle eine 1 enthält:
\[ \begin{split} -\frac{1}{n} \sum_{i=1}^n (y_i - g(\mathbf{w}' \mathbf{x_i})) \cdot 1 &= 0\\ -\frac{1}{n} \sum_{i=1}^n y_i + \frac{1}{n} \sum_{i=1}^n g(\mathbf{w}' \mathbf{x_i}) &= 0\\ \frac{1}{n} \sum_{i=1}^n g(\mathbf{w}' \mathbf{x_i}) &= \frac{1}{n} \sum_{i=1}^n y_i\\ \end{split} \]
Wow, in der letzten Zeile sehen wir nun genau das gesuchte Resultat. Am Optimum (der Modellparameter) muss gelten, dass der Durchschnitt über die \(y\)-Werte genau dem Durchschnitt über die Modelloutputs entspricht.
3.1.4 Decision Boundaries
Wir haben nun gesehen, wie das logistische Regressionsmodell aussieht, wie es trainiert wird und wie es auf unser kleines Beispiel angewendet wird. Doch Ihnen ist wahrscheinlich immer noch nicht klar, warum wir dabei von einem linearen Klassifikationsmodell sprechen (die Sigmoid Funktion ist schliesslich alles andere als linear).
Um zu verstehen, warum es sich um ein lineares Modell handelt, schauen wir uns nun die so genannte Decision Boundary des Modells an.
HinweisDecision Boundary
Die Decision Boundary ist in einem gewissen Sinn eine Grenze. Auf der einen Seite der Grenze ist der Wertebereich der Input-Variablen \(\mathbf{x}_i\), für den \(\hat{y}_i=1\) vorhergesagt wird. Auf der anderen Seite der Grenze ist der Wertebereich, für den \(\hat{y}_i=0\) vorhergesagt wird. Die Decision Boundary bezieht sich also auf die Input-Variablen und zeigt uns, wo welche Vorhersagen gemacht werden.
Wir haben oben gesehen, dass das logistische Regressionsmodell (kompakt) wie folgt spezifiziert ist:
\[ p(y_i = 1 \mid \mathbf{x}_i) = \frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}} \]
Wir schreiben dieses Modell nun etwas um, so dass wir am Schluss die Decision Boundary herleiten können. Dazu wollen wir die Gleichung so verändern, dass wir auf der linken Seite die Odds haben. Die Odds sind definiert als die Erfolgswahrscheinlichkeit, also \(p(y_i = 1 \mid \mathbf{x}_i)\), dividiert durch die Misserfolgswahrscheinlichkeit, also \(1 - p(y_i = 1 \mid \mathbf{x}_i)\).
Fragen
Wir versuchen hier erstmal die Odds ganz allgemein zu verstehen. Odds sind vor allem im Wettgeschäft eine wichtige Grösse.
- Die Erfolgswahrscheinlichkeit ist 0.1. Was sind die Odds?
- Die Odds sind 1/1 (oder 1:1). Was ist die Erfolgswahrscheinlichkeit?
TippLösung
Die Erfolgswahrscheinlichkeit ist \(p=0.1\). Die Odds sind dementsprechend \(\frac{p}{1-p}=\frac{1/10}{9/10}=\frac{1}{10}\frac{10}{9}=\frac{1}{9}\). Die Odds sind also 1/9 oder 1:9.
Wenn die Odds 1/1 sind, dann lässt sich die Erfolgschwahrscheinlichkeit wie folgt herleiten:
\[\begin{align} \frac{p}{1-p} &= 1\\ p &= 1-p\\ 2p &= 1\\ p &= \frac{1}{2} \end{align}\]
Odds von 1:1 heissen also nichts anderes, als dass sowohl die Erfolgs- als auch die Misserfolgswahrscheinlichkeit genau 50% sind.
Die mathematische Umformung (in Odds) für die logistische Regression geht wie folgt:
\[\begin{align} \frac{p(y_i = 1 \mid \mathbf{x}_i)}{1-p(y_i = 1 \mid \mathbf{x}_i)} &= \frac{\frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}}}{1 - \frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}}}\\ &= \frac{\frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}}}{\frac{1+e^{-(\mathbf{w}' \mathbf{x_i})}}{1+e^{-(\mathbf{w}' \mathbf{x_i})}} - \frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}}}\\ &= \frac{\frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}}}{\frac{e^{-(\mathbf{w}' \mathbf{x_i})}}{1+e^{-(\mathbf{w}' \mathbf{x_i})}}}\\ &= \frac{1}{1+e^{-(\mathbf{w}' \mathbf{x_i})}} \cdot \frac{1+e^{-(\mathbf{w}' \mathbf{x_i})}}{e^{-(\mathbf{w}' \mathbf{x_i})}}\\ &= e^{(\mathbf{w}' \mathbf{x_i})} \end{align}\]
In einem letzten Schritt können wir nun noch auf beiden Seiten den Logarithmus nehmen:
\[\begin{align} \log\left(\frac{p(y_i = 1 \mid \mathbf{x}_i)}{1-p(y_i = 1 \mid \mathbf{x}_i)}\right) &= \log\left(e^{(\mathbf{w}' \mathbf{x_i})}\right)\\ &= \mathbf{w}' \mathbf{x_i} \end{align}\]
Diese letzte Form wird Log-Odds genannt, weil wir auf der linken Seite der Gleichung nun den Logarithmus der Odds haben. Warum haben wir all das gemacht? Sie sehen, dass wir auf der rechten Seite der Gleichung nun die altbekannte lineare Form haben. Diese letzte Gleichung ist darum nun einfach zu handhaben, wenn es um die Berechnung der Decision Boundary geht.
Eine Input-Variable
Schauen wir uns in einem ersten Schritt an, wie die Decision Boundary aussieht, wenn wir nur eine Input-Variable haben (wie in unserem kleinen Beispiel). Die Log-Odds sehen in diesem Fall wie folgt aus:
\[ \log\left(\frac{p(y_i = 1 \mid \mathbf{x}_i)}{1-p(y_i = 1 \mid \mathbf{x}_i)}\right) = w_0 + w_1 \cdot x_{i1} \]
Wir haben oben bereits kurz den Threshold angesprochen. Hier wählen wir einen Threshold von 50% (= 0.5). Die Decision Boundary wird die Input-Varablenwerte darstellen, die genau zu einem Modelloutput von 50% führen.
Wir können den gewählten Threshold-Wert in obige Gleichung einsetzen und kriegen folgendes:
\[ \begin{split} \log\left(\frac{0.5}{1-0.5}\right) &= w_0 + w_1 \cdot x_{i1}\\ \log\left(1\right) &= w_0 + w_1 \cdot x_{i1}\\ 0 &= w_0 + w_1 \cdot x_{i1} \end{split} \]
Indem wir nach \(x_{i1}\) auflösen, kriegen wir eine Formel, die uns den Input-Variablenwert gibt, der zu einem Modelloutput von genau 50% führt:
\[ x_{i1} = -\frac{w_0}{w_1} \]
Frage
Wo liegt die Decision Boundary bei unserem kleinen Beispiel?
TippLösung
\[ x_{i1} = -\frac{w_0}{w_1} = - \frac{0.15}{0.99} \approx -0.15 \] Der Input-Variablenwert, der zu einer Wahrscheinlichkeit von 0.5 führt, ist ca. -0.15. Alle \(x\)-Werte kleiner als -0.15 werden als \(\hat{y}_i=0\) klassifiziert, alle \(x\)-Werte grösser als -0.15 als \(\hat{y}_i=1\).
Die folgende Abbildung zeigt die berechnete Decision Boundary auch noch grafisch:
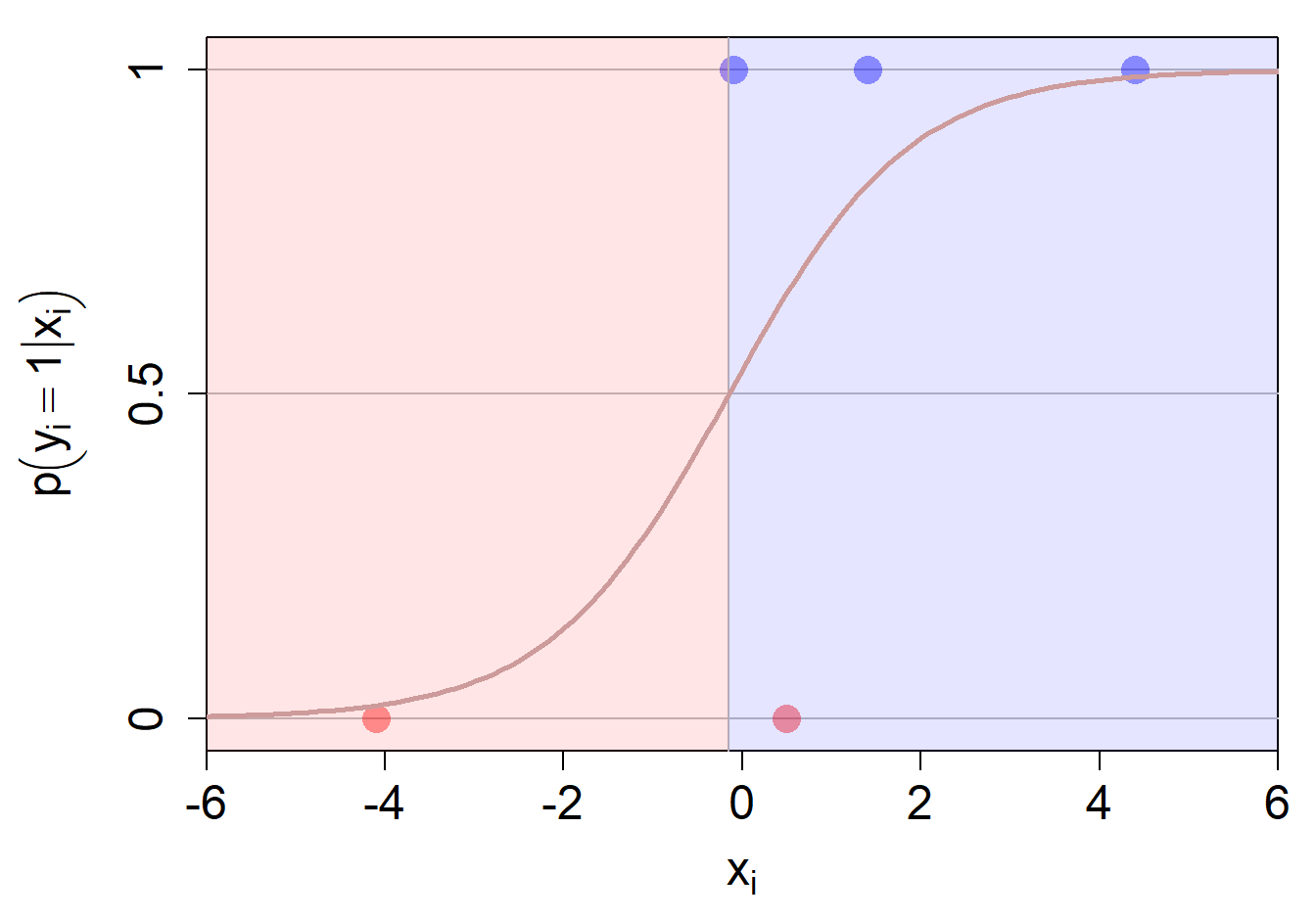
Wenn wir also nur eine Input-Variable haben, dann ist die Decision Boundary eine Vertikale (hier am Punkt \(x=-0.15\)). Wir werden später sehen, dass sich diese Vertikale je nach gewähltem Threshold verschiebt.
Zwei Input-Variablen
Wenn wir zwei Input-Variablen haben, dann können wir die Decision Boundary, gegeben ein Threshold \(p^*\), wie folgt herleiten:
\[\begin{align} \log\left(\frac{p^*}{1-p^*}\right) &= w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2}\\ w_1 \cdot x_{i1} &= \log\left(\frac{p^*}{1-p^*}\right) - w_0 - w_2 \cdot x_{i2}\\ x_{i1} &= \color{blue}{\frac{\log\left(\frac{p^*}{1-p^*}\right) - w_0}{w_1}} \color{red}{- \frac{w_2}{w_1}} \color{black}{\cdot x_{i2}} \end{align}\]
Diese Form sollte Ihnen irgendwie bekannt vorkommen. Die Decision Boundary kann bei zwei Input-Variablen als Gerade im Koordinatensystem mit \(x_{i1}\) auf der y-Achse und \(x_{i2}\) auf der x-Achse dargestellt werden. Die Gerade hat eine Konstante (blauer Teil) und eine Steigung (roter Teil).
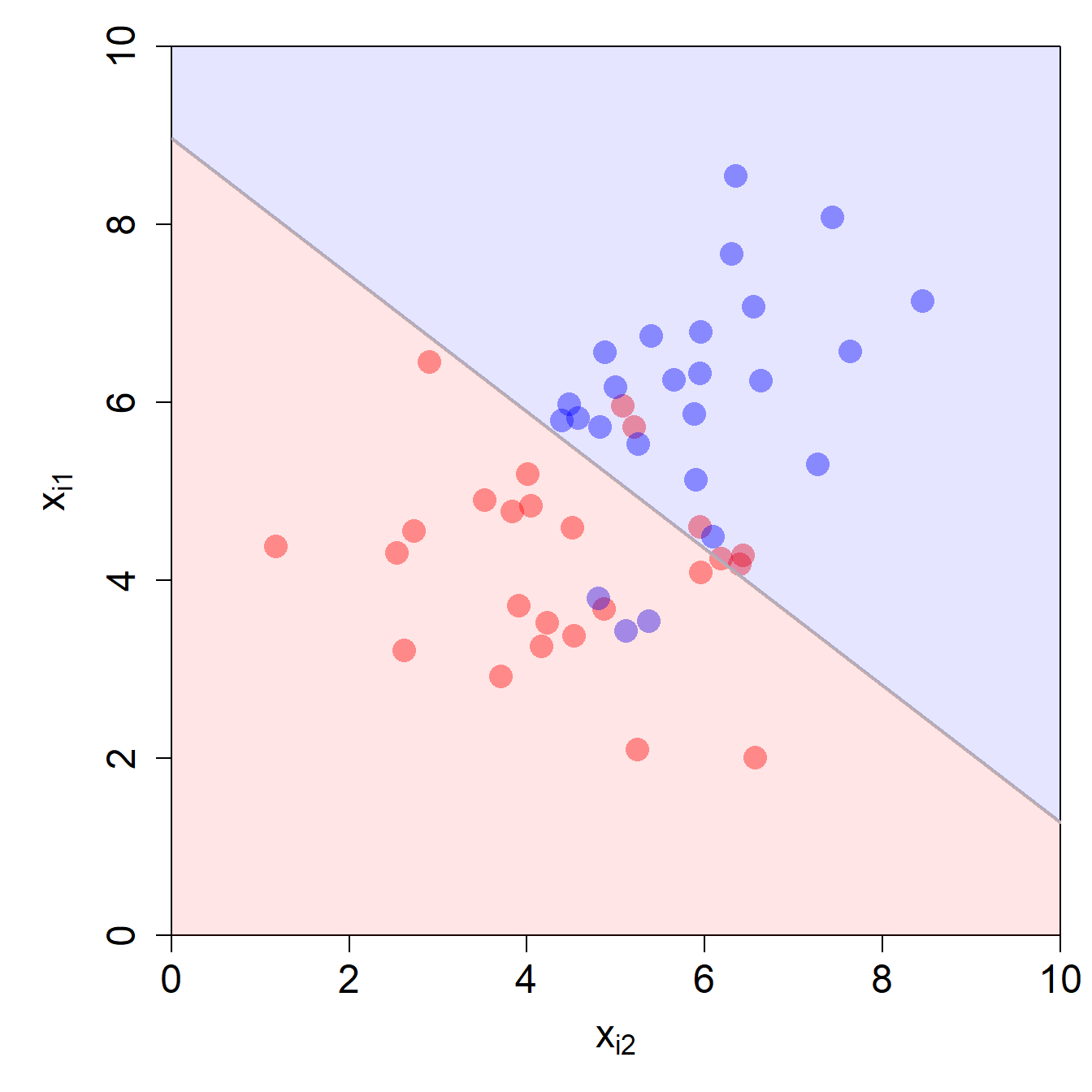
Die graue Gerade repräsentiert alle Kombinationen der Input-Variablen \(x_{i1}\) und \(x_{i2}\), für welche das Modell eine Wahrscheinlichkeit ausspuckt, die genau dem gewählten Threshold \(p^*\) (hier 0.5) entspricht.
HinweisInput Space
Wir werden Abbildungen, wie diejenige oben noch oft sehen. Sie zeigt hier den Input Space für dieses Problem mit zwei Input-Variablen.
Der Input Space ist ein “Raum”, der alle möglichen Kombinationen der Input-Variablenwerte enthält. Der Wert der Output-Variable ist in dieser Abbildung ebenfalls kodiert, nämlich als Farbe der Datenpunkte.
Jedes Klassifikationsmodell versucht, diesen Input Space so zu segmentieren, dass die Kategorien der Output-Variable möglichst optimal voneinander abgetrennt werden.
Wichtig: wir sehen vom ein- und zweidimensionalen Beispiel, das die Decision Boundary immer linear ist. Darum gilt das logistische Regressionsmodell als einfaches Modell: es kann im Prinzip nur lineare Decision Boundaries fitten.
Lineare Separierbarkeit
Weder in unserem kleinen Beispiel mit einer Input-Variable noch im obigen Beispiel mit zwei Input-Variablen sind die Daten linear separierbar. Das heisst, es gibt keinen Threshold-Wert, mit dem die Decision Boundary die Datenpunkte perfekt separieren könnte.
Es gibt jedoch, ähnlich wie bei der polynomischen Regression (Abschnitt 2.7), die Möglichkeit neue Input-Variablen zu kreieren und den Input Space so zu erweitern. So wird das Modell flexibler.
Was zum Beispiel mit der Decision Boundary passiert, wenn wir in dem obigen Beispiel mit zwei Input-Variablen eine dritte Input-Variable \(x_{i1}^2\) ins Modell nehmen, sehen Sie in folgender Abbildung:
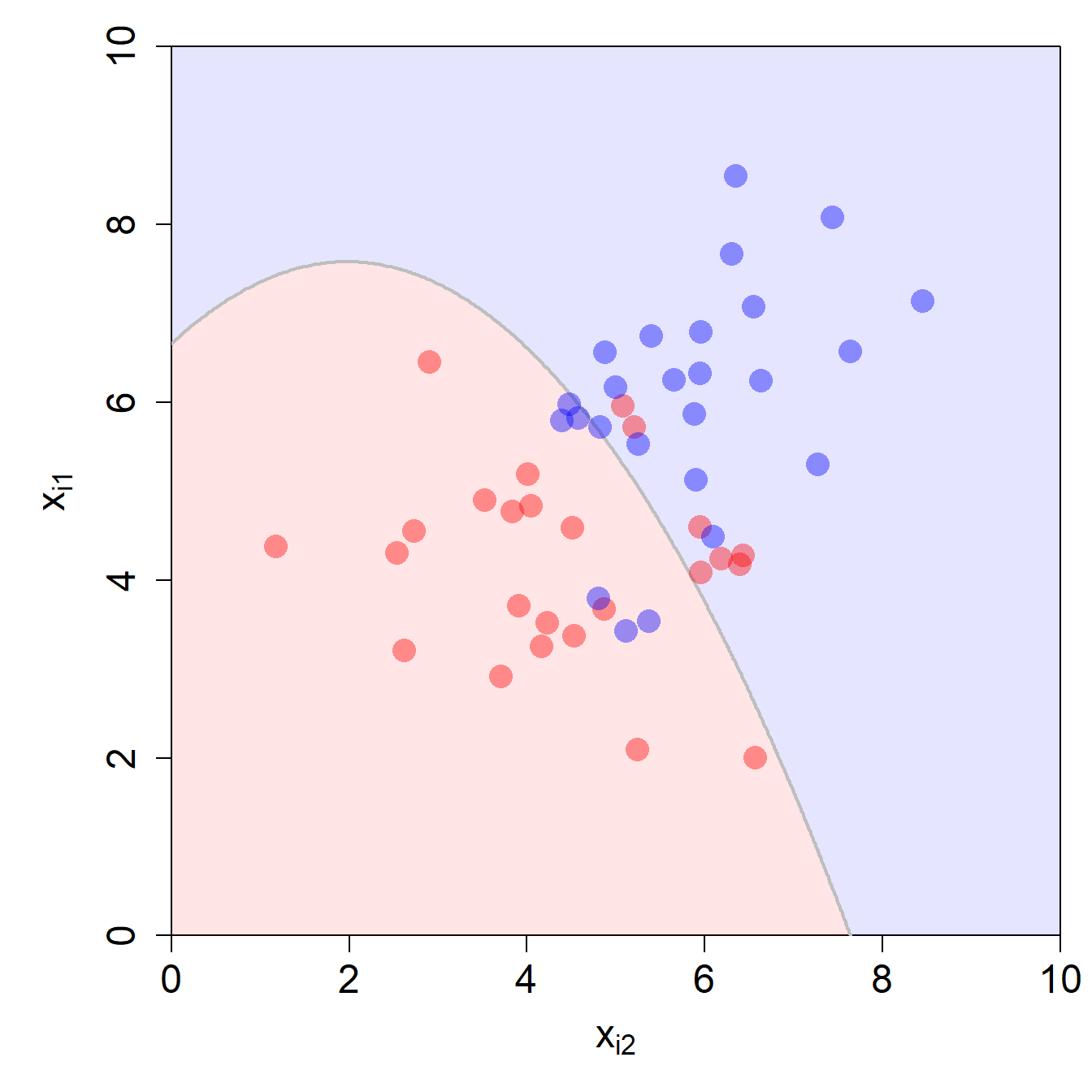
Wow, das Modell ist jetzt schon viel flexibler. Die Decision Boundary im ursprünglichen Input Space hat nun eine quadratische Form. Ganz wichtig: auch dieses Modell bleibt aber linear in den Parameter. Man muss bei solchen neuen polynomischen Input-Variablen aufpassen, denn man landet so schnell im Overfitting. Dem können wir mit einer Portion Regularisierung begegnen.
3.2 Naive Bayes
Ein sehr einfaches, aber oft erstaunlich gut performendes Klassifikationsmodell ist Naive Bayes. Dieses Modell beruht auf dem Satz von Bayes, den Sie vielleicht bereits kennen.
VorsichtSatz von Bayes
Im einfachsten Fall kann der Satz von Bayes wie folgt aufgeschrieben werden. Gegeben seien zwei Ereignisse \(A\) und \(B\). Tritt das Ereignis nicht ein, bezeichnen wir es als \(\bar{A}\), respektive \(\bar{B}\) (sogenannte Komplemente).
Die Wahrscheinlichkeit von Ereignis \(A\), gegeben \(B\) ist gemäss dem Satz von Bayes:
\[ P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)} \]
Der Nenner kann nach dem Gesetz der totalen Wahrscheinlichkeit berechnet werden:
\[ P(B) = P(B \mid A) \cdot P(A) + P(B \mid \bar{A}) \cdot P(\bar{A}) \]
Nehmen Sie beispielsweise an, Sie haben eine Prüfung an einer Schule durchgeführt. 90% der Teilnehmenden haben die Prüfung bestanden (10% nicht). Sie befragen nach der Prüfung alle Teilnehmenden, ob sie sich auf die Prüfung vorbereitet haben. Von den Teilnehmenden, welche die Prüfung bestanden haben, haben sich 80% vorbereitet. Von den Teilnehmenden, die nicht bestanden haben, haben sich lediglich 10% vorbereitet.
Es sei \(A\) das Ereignis, dass die Prüfung bestanden wurde und \(B\) das Ereignis, dass eine Prüfungsvorbereitung stattfand. Was ist die Wahrscheinlichkeit, die Prüfung zu bestehen, wenn man sich vorbereitet hat?
Die Antwort lässt sich einfach mit dem Satz von Bayes beantworten. Gegeben ist:
- \(P(A) = 0.9\)
- \(P(\bar{A}) = 0.1\)
- \(P(B \mid A) = 0.8\)
- \(P(B \mid \bar{A}) = 0.1\)
\[ \begin{split} P(A \mid B) &= \frac{P(B \mid A) \cdot P(A)}{P(B)}\\ &= \frac{0.8 \cdot 0.9}{0.8 \cdot 0.9 + 0.1 \cdot 0.1}\\ &= \frac{0.72}{0.72 + 0.01} = 0.9863 \end{split} \]
Wenn Sie sich also auf die Prüfung vorbereiten, dann sind Sie fast sicher (ca. 99%), dass Sie die Prüfung bestehen werden.
3.2.1 Modellspezifikation
Das Naive Bayes Modell kann folgendermassen spezifiziert werden. Dabei wenden wir den Satz von Bayes an (\(y_i=1\) ist hier gewissermassen das Ereignis A, während die Beobachtung der Input-Variablen \(\mathbf{x}_i\) das Ereignis B darstellt):
\[ p(y_i = 1 \mid \mathbf{x}_i) = \frac{p(\mathbf{x}_i \mid y_i = 1) \cdot p(y_i = 1)}{p(\mathbf{x}_i)} \]
Es lohnt sich, hier kurz zu überlegen, was die einzelnen Komponenten in dieser Modellspezifikation sind:
- Der linke Teil ist die Wahrscheinlichkeit, dass wir für die \(i\)-te Beobachtung die Kategorie 1 beobachten, gegeben die beobachteten Input-Variablenwerte. Im Prinzip ist es derselbe Term wie der linke Teil des logistischen Regressionsmodells. Im Kontext des Naive Bayes Modell wird dieser Term bzw. diese Wahrscheinlichkeit Posterior genannt.
- Der erste Teil rechts oben, also \(p(\mathbf{x}_i \mid y_i = 1)\), ist die Wahrscheinlichkeit der beobachteten Input-Werte der Beobachtung \(i\), gegeben sie gehört der Kategorie 1 an. Dieser Teil der Spezifikation wird Likelihood genannt.
- Der zweite Teil rechts oben, also \(p(y_i = 1)\), ist die a-priori Wahrscheinlichkeit, die Kategorie 1 zu beobachten. Diese Wahrscheinlichkeit wird in der Fachsprache Prior genannt.
- Der Nenner auf der rechten Seite ist die Wahrscheinlichkeit, die gegebenen Input-Variablenwerte zu beobachten, und zwar unabhängig davon ob die Beobachtung der Kategorie 1 oder 0 angehört. Oft wird dieser Teil Evidence oder Marginal Likelihood genannt. Mit dem Gesetz der totalen Wahrscheinlichkeit kann dieser Term berechnet werden:
\[ p(\mathbf{x}_i) = p(\mathbf{x}_i \mid y_i = 1) \cdot p(y_i = 1) + p(\mathbf{x}_i \mid y_i = 0) \cdot p(y_i = 0) \]
Mit dem Naive Bayes Modell sehen wir nun zum ersten Mal ein generatives Modell (siehe Abschnitt 1.4.3), denn wir schätzen im Zähler der Modellspezifikation nichts anderes als die gemeinsame Verteilung von \(\mathbf{x}_i\) und \(y_i\):
\[ p(\mathbf{x}_i \mid y_i) \cdot p(y_i) = p(\mathbf{x}_i,\, y_i) \]
HinweisWarum dieses Modell naiv genannt wird?
Der zentrale Aspekt beim Naive Bayes Modell ist eine Unabhängigkeitsannahme. Warum brauchen wir eine Unabhängigkeitsannahme? Weil es äusserst schwierig ist, die Likelihood \(p(\mathbf{x}_i \mid y_i = 1)\) aus Daten zu schätzen.
Nehmen wir an, wir haben 10 Input-Variablen, die alle binär sind (0/1, also zwei mögliche Werte annehmen können). In diesem Fall müssten wir aus den Daten eine gemeinsame Wahrscheinlichkeit (engl. Joint Probability) mit \(2^{10}=1024\) möglichen Kombinationen schätzen, und zwar für jede mögliche Kategorie der Output-Variable. Etwas allgemeiner würde gelten, dass wenn wir \(p\) binäre Input-Variaben haben, die gemeinsame Wahrscheinlichkeit von \(2^p\) möglichen Kombinationen von Input-Variablenwerten für jede der \(C\) Kategorien (hier \(C=2\)) aus Daten geschätzt werden müsste.
In der Praxis ist das bereits ab einem kleinen \(p\) unsinning: viele der möglichen Kombinationen würden im Trainingsdatensatz sehr selten oder gar nicht vorkommen, was eine robuste Schätzung dieser Wahrscheinlichkeiten verunmöglicht. Die so geschätzten Wahrscheinlichkeiten sind eine weitere Art wie sich Overfitting äussern kann.
Um dieses Problem zu beheben, machen wir beim Naive Bayes Modell folgende Unabhängigkeitsannahme für die Likelihood:
\[ p(\mathbf{x}_i \mid y_i = 1) = p(x_{i1} \mid y_i = 1) \cdot p(x_{i2} \mid y_i = 1) \cdot \ldots \cdot p(x_{ip} \mid y_i = 1) \cdot \]
Anstatt die gemeinsame Wahrscheinlichkeit müssen wir hier nur die Randwahrscheinlichkeiten für jede der \(p\) Input-Variablen separat schätzen und diese dann miteinander multiplizieren. Wir befolgen hier die bekannte Regel aus der Wahrscheinlichkeitsrechnung, dass wenn zwei Ereignisse \(A\) und \(B\) unabhängig sind, die gemeinsame Wahrscheinlichkeit wie folgt berechenbar ist:
\[ P(A, B) = P(A) \cdot P(B) \]
Diese Unabhängigkeitsannahme ist eine starke Vereinfachung der Realität. Wenn wir beispielsweise modellieren, ob jemand zahlungsunfähig wird (\(y_i=1\)) oder nicht, dann besagt die Annahmen, dass das Einkommen (gegeben es kommt zu einer Zahlungsunfähigkeit) unabhängig ist vom Beschäftigungsgrad (gegeben es kommt zu einer Zahlungsunfähigkeit). Diese beiden Input-Variablen korrelieren in der Praxis jedoch sicherlich sehr stark und sind nicht unabhängig.
Das erstaunliche ist jedoch, dass Naive Bayes trotz dieser Annahme in der Praxis oft gut funktioniert. Um zu verstehen, warum das so ist, hilft der Bias-Variance-Tradeoff. Die Unabhängigkeitsannahme verstärkt zwar den Bias des Modells. Gleichzeitig reduzieren wir aber die Varianz (Overfitting) substantiell, da das Modell so viel, viel einfacher wird. Die Reduktion der Varianz scheint den Anstieg im Bias-Term oft zu überwiegen.
3.2.2 Modelltraining
Es wurde oben bereits angedeutet, dass Modelltraining im Fall von Naive Bayes heisst, dass verschiedene Wahrscheinlichkeiten aus den Trainingsdaten geschätzt werden müssen:
- Die Priors \(p(y_i = 1)\) und \(p(y_i = 0)\)
- Die Randwahrscheinlichkeiten \(p(x_{i1} \mid y_i = 1)\), \(p(x_{i2} \mid y_i = 1)\), etc. für alle Beobachtungen im Trainingsdatensatz, die der Kategorie 1 angehören.
- Die Randwahrscheinlichkeiten \(p(x_{i1} \mid y_i = 0)\), \(p(x_{i2} \mid y_i = 0)\), etc. für alle Beobachtungen im Trainingsdatensatz, die der Kategorie 0 angehören.
Wir schauen uns das Modelltraining konkret für unser einfaches Klassifikationsproblem von oben mit folgender Ausgangslage an:
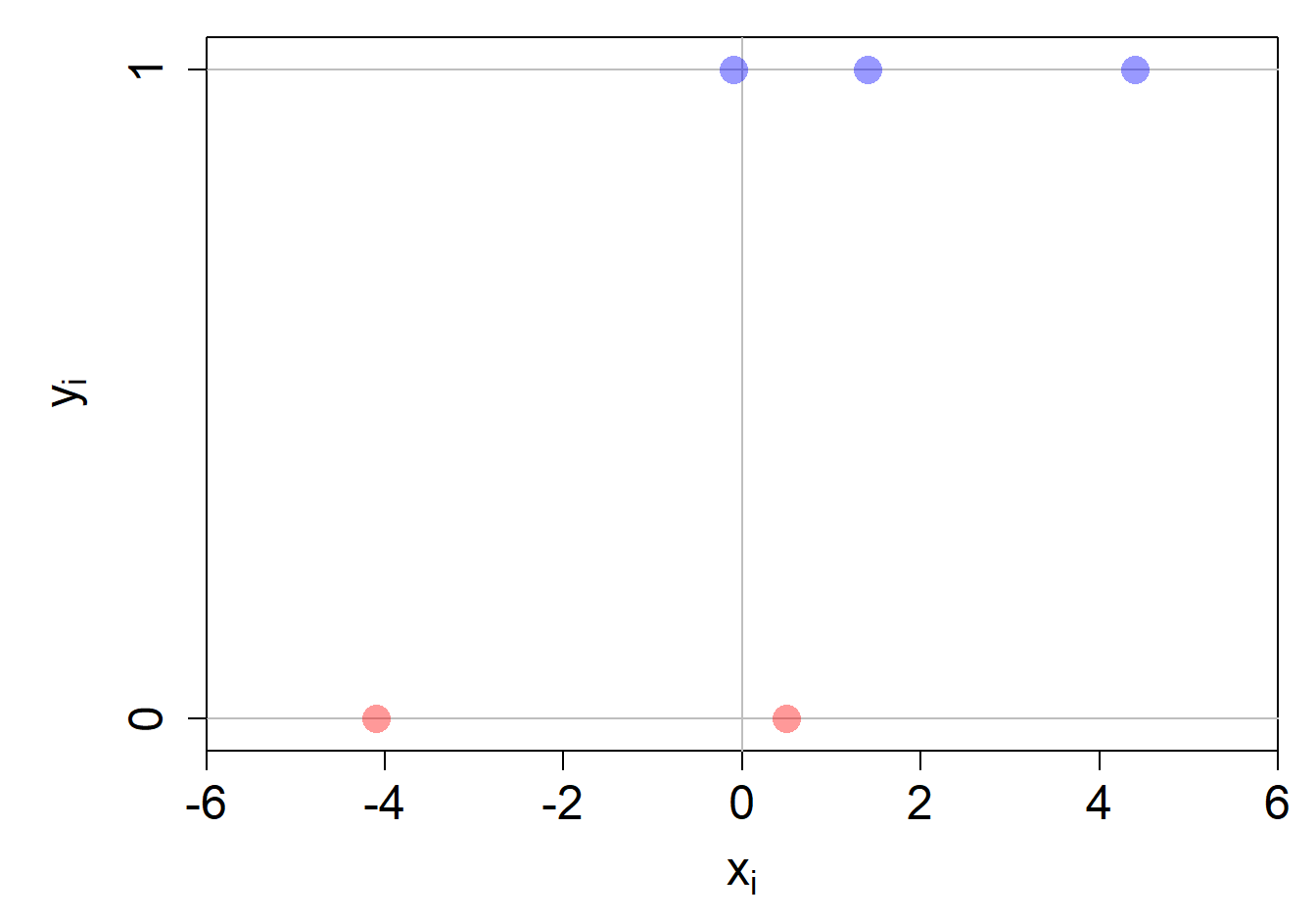
Wichtig: wir haben hier nur eine Input-Variable, weshalb die Unabhängigkeitsannahme des Naive Bayes Modells hier nicht ins Gewicht fallen wird.
Die Priors können ganz einfach als relative Häufigkeiten basierend auf dem Trainingsdatensatz geschätzt werden. Für unser Beispiel kriegen wir folgende Priors:
- \(p(y_i = 1) = \frac{3}{5} = 0.6\) (die blauen Beobachtungen)
- \(p(y_i = 0) = \frac{2}{5} = 0.4\) (die roten Beobachtungen)
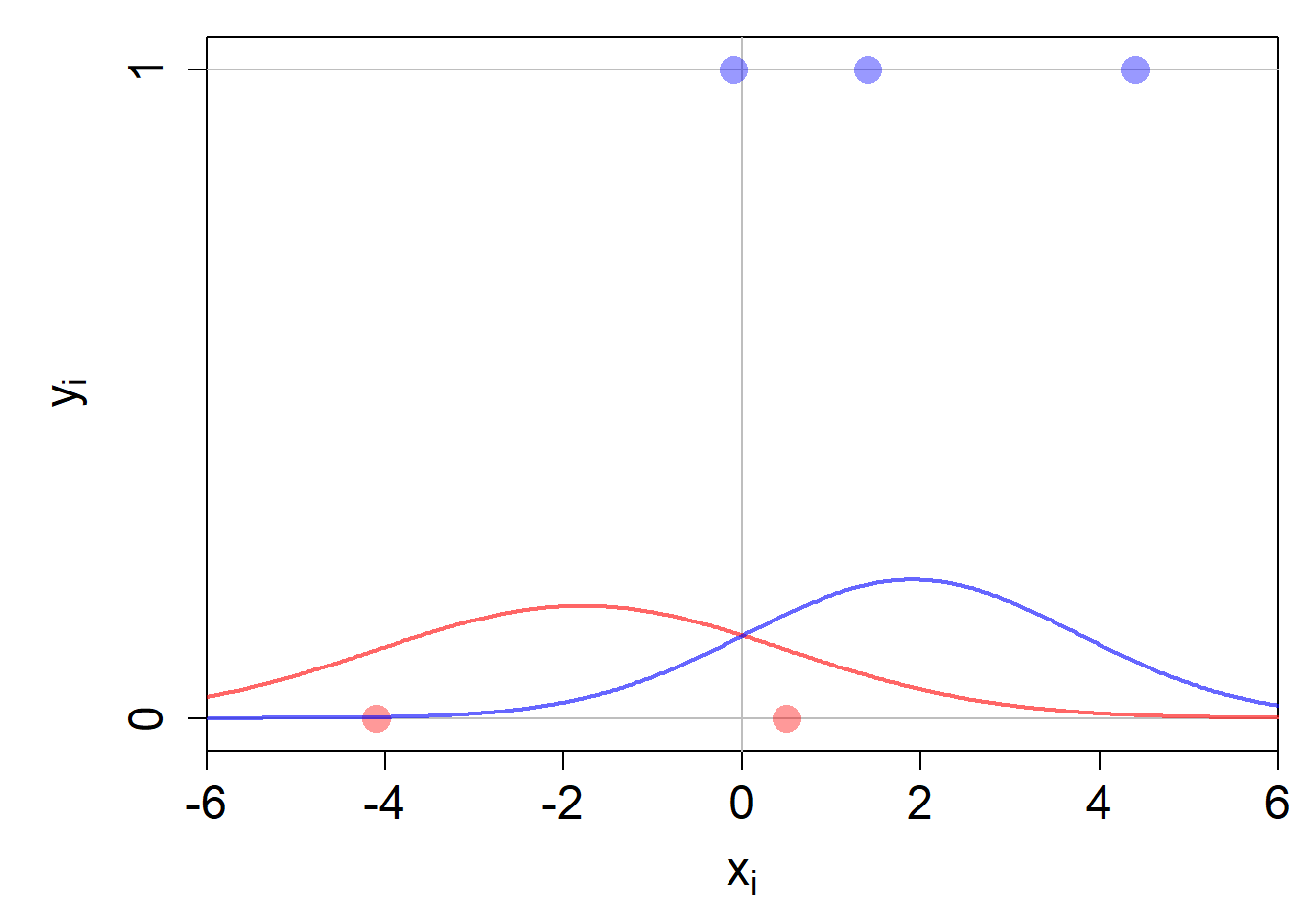
In unserem Fall haben wir eine quantitative Input-Variable. Die Randwahrscheinlichkeiten werden für diesen Fall als Normalverteilungen, einmal für die Kategorie \(y_i=1\) und einmal für die Kategorie \(y_i=0\) geschätzt.
Für \(y_i=0\) ergibt sich die Schätzung von \(p(x_{i} \mid y_i = 0) = \mathcal{N}\left(\mu_0, \sigma_0^2\right)\), wobei
- \(\mu_0=\frac{1}{2}(-4.1 + 0.5) = -1.8\)5
- \(\sigma_0^2 = \frac{1}{2}\left((-4.1 - (-1.8))^2 + (0.5 - (-1.8))^2\right) = 5.29\)6
Für \(y_i=1\) ergibt sich die Schätzung von \(p(x_{i} \mid y_i = 1) = \mathcal{N}\left(\mu_1, \sigma_1^2\right)\), wobei
- \(\mu_1=\frac{1}{3}(-0.1 + 1.4 + 4.4) = 1.9\)
- \(\sigma_1^2 = \frac{1}{3}\left((-0.1 - 1.9)^2 + (1.4 - 1.9)^2 + (4.4 - 1.9)^2\right) = 3.5\)
Die folgende Abbildung zeigt die Dichtefunktionen der beiden geschätzten Normalverteilungen, die für jeden möglichen Wert von \(x\) einen Dichtewert zurückgeben.
3.2.3 Vorhersagen
Als Beispiel können wir nun den Posterior \(p(y_i = 1 \mid x_i)\) für den Wert \(x_i=2\) berechnen:
\[\begin{align} p(y_i = 1 \mid x_i = 2) &= \frac{p(x_i = 2 \mid y_i = 1) \cdot p(y_i = 1)}{p(x_i = 2)}\\ &= \frac{\mathcal{N}(x_i=2 \mid \mu_1, \sigma_1^2) \cdot p(y_i = 1)}{\mathcal{N}(x_i=2 \mid \mu_1, \sigma_1^2) \cdot p(y_i = 1) + \mathcal{N}(x_i=2 \mid \mu_0, \sigma_0^2) \cdot p(y_i = 0)}\\ &= \frac{0.213 \cdot 0.6}{0.213 \cdot 0.6 + 0.044 \cdot 0.4}\\ &= 0.88 \end{align}\]
Für einen Input-Wert \(x_i=2\) ist die Wahrscheinlichkeit, dass die Beobachtung der Kategorie 1 angehört, also 88%.
Wir können die Posterior Wahrscheinlichkeiten, \(p(y_i = 1 \mid x_i)\) und \(p(y_i = 0 \mid x_i)\), für jeden möglichen Wert von \(x_i\) berechnen und als Kurven in unser Diagramm einzeichnen:
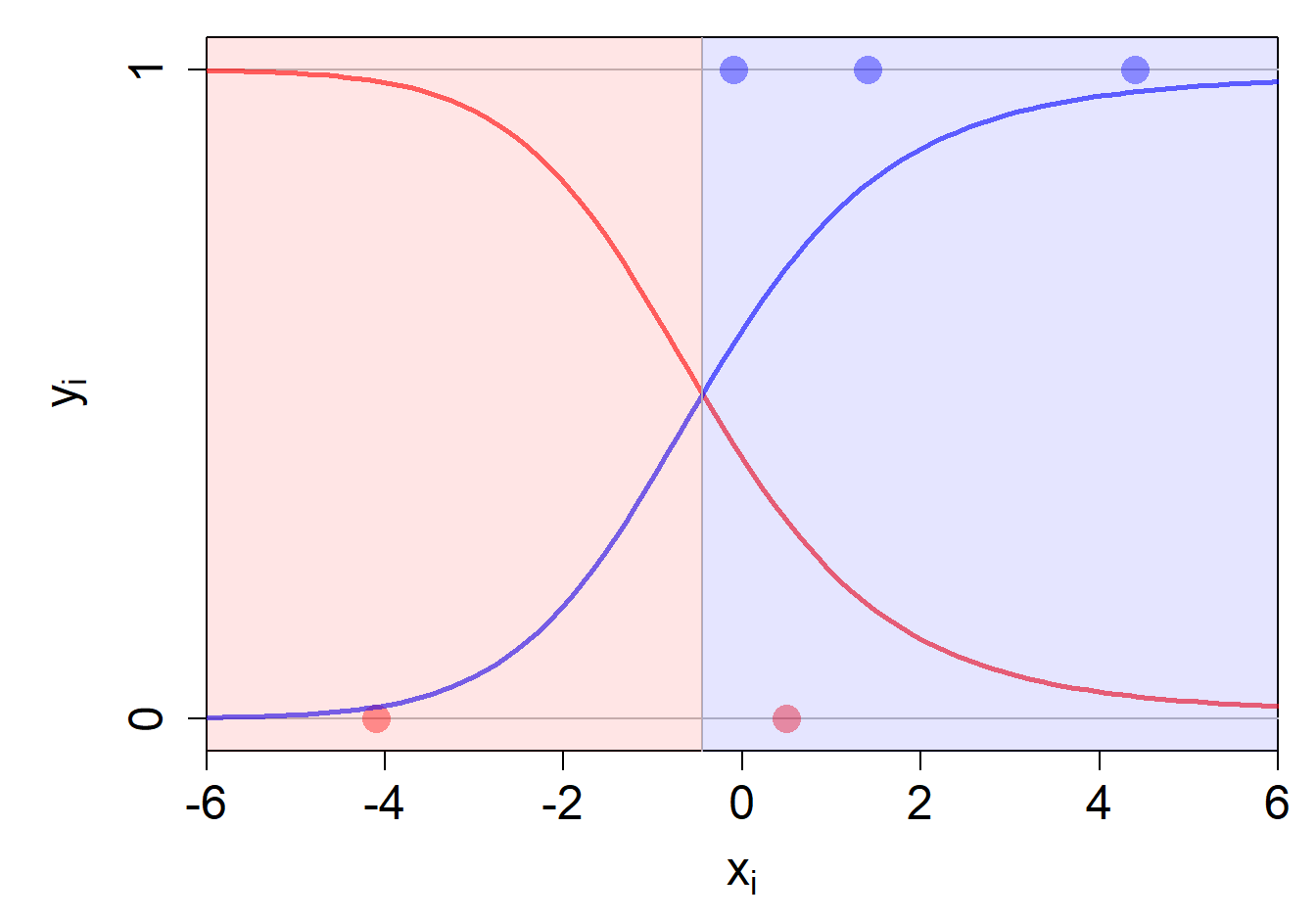
Der Ort, an dem sich die beiden Kurven kreuzen, stellt die Decision Boundary dar. Das macht auch irgendwie Sinn, denn es ist ja der Ort, an dem die Posterior Wahrscheinlichkeit der einen Kategorie plötzlich kleiner ist als diejenige der anderen Kategorie. Hier ist das am Ort \(x=-0.44\) (die Berechnung dieses Punkts ist etwas komplexer, weshalb wir sie hier nicht anschauen).
Hier noch ein paar Abschlussbemerkungen:
- Das Naive Bayes Modell funktioniert problemlos für \(C>2\) Kategorien in der Outputkategorie. Wir berechnen die bedingten Randwahrscheinlichkeiten sowie den Prior einfach auch für die weiteren Kategorien und können so den entsprechend angepassten Posterior berechnen. Für gegebene Input-Variablenwerte \(\mathbf{x}_i\) wird die Klasse mit der höchsten Posterior Wahrscheinlichkeit vorhergesagt.
- Wir hatten in unserem kleinen Beispiel nur eine numerische Input-Variable. Ein Naive Bayes Modell kann gut mit gemischten Input-Variablen umgehen. Wir können also sowohl numerische als auch kategorische Input-Variablen im Modell drin haben. Die entsprechenden Randwahrscheinlichkeiten werden dabei einfach miteinander multipliziert.
- Fehlt für eine Beobachtung der Wert einer Input-Variable, dann kann diese Input-Variable einfach ignoriert werden. Warum das so ist, kann in folgender (optionalen) Box nachvollzogen werden.
VorsichtFehlende Input-Werte in Naive Bayes (optional)
Nehmen wir an, wir haben zwei Input-Variablen \(x_{i1}\) und \(x_{i2}\). Nun fehlt uns bei einer Beobachtung der Wert für die Variable \(x_{i2}\).
Wir können nun die Variable \(x_{i2}\) aus der rechten Seite der Modellspezifikation raus marginalisieren. Das Prinzips des Marginalisierens haben Sie vermutlich bereits kennen gelernt. Es gilt folgende allgemeine Regel: \(\sum_{A} P(A,B) = P(B)\). Diese Regel wenden wir nun hier an:
\[\begin{align} {\color{Red}\sum_{x_{i2}}} \frac{p(x_{i1} \mid y_i = 1) \cdot p(x_{i2} \mid y_i = 1) \cdot p(y_i = 1)}{p(x_{i1} \mid y_i = 1) \cdot p(x_{i2} \mid y_i = 1) \cdot p(y_i = 1) + p(x_{i1} \mid y_i = 0) \cdot p(x_{i2} \mid y_i = 0) \cdot p(y_i = 0)}\\ = \frac{p(x_{i1} \mid y_i = 1) \cdot {\color{Red}\sum_{x_{i2}} p(x_{i2} \mid y_i = 1)} \cdot p(y_i = 1)}{p(x_{i1} \mid y_i = 1) \cdot {\color{Red}\sum_{x_{i2}} p(x_{i2} \mid y_i = 1)} \cdot p(y_i = 1) + p(x_{i1} \mid y_i = 0) \cdot {\color{Red}\sum_{x_{i2}} p(x_{i2} \mid y_i = 0)} \cdot p(y_i = 0)}\\ = \frac{p(x_{i1} \mid y_i = 1) \cdot {\color{Red} 1} \cdot p(y_i = 1)}{p(x_{i1} \mid y_i = 1) \cdot {\color{Red} 1} \cdot p(y_i = 1) + p(x_{i1} \mid y_i = 0) \cdot {\color{Red} 1} \cdot p(y_i = 0)}\\ = \frac{p(x_{i1} \mid y_i = 1) \cdot p(y_i = 1)}{p(x_{i1} \mid y_i = 1) \cdot p(y_i = 1) + p(x_{i1} \mid y_i = 0) \cdot p(y_i = 0)}\\ \end{align}\]
Diese Umformung oben ist nur dank der Unbhängigkeitsannahme möglich. Ausserdem verwenden wir die Tatsache, dass \(\sum_{x_{i2}} p(x_{i2} \mid y_i = 1) = 1\), d.h. wenn wir die Randwahrscheinlichkeiten über alle möglichen Werte von \(x_{i2}\) summieren, dann muss per Definition 1 resultieren.
3.2.4 Spam Filter
Zum Schluss schauen wir uns hier (erstmal nur konzeptionell) die Anwendung des Naive Bayes Modells für einen Spam Filter an. Der Spam Filter soll eine gegebene Email möglichst korrekt in die Kategorien Spam (\(y_i=1\)) oder Ham (\(y_i=0\)) klassifizieren.
Die Trainingsdaten bestehen in diesem Fall aus \(n\) Emails. Eine Sammlung von Emails sind sogenannte unstrukturierte Daten und da muss man sich überlegen, wie man die Daten in eine strukturierte Form bringt. Oder in anderen Worten, wie kommt man von einer Email zu einem Input-Vektor \(\mathbf{x}_i\)? Eine Möglichkeit ist der sogenannte Bag-of-Words Ansatz. Dabei geht man folgendermassen vor:
- Man bestimmt die häufigsten Wörter im Trainingsdatensatz (d.h., in den Emails, die wir für das Training verwenden werden).
- Das erste Wort in diesem Set von häufig vorkommenden Wörtern wird durch die erste Input-Variable \(x_{i1}\) repräsentiert, das zweite Wort durch die zweite Input-Variable \(x_{i2}\), usw. Für eine Beobachtung \(i\) (bzw. die \(i\)-te Email) ist die Input-Variable \(x_{i1}=1\) falls das erste Wort in der Email vorkommt und sonst 0. Dasselbe gilt natürlich für alle anderen Input-Variablen. So kann eine Email in einen fixen Input-Vektor von Nullen und Einsen transformiert werden.
Folgende Abbildung illustriert den Bag-of-Words Ansatz für ein ganz kleines Beispiel:

Wir schauen uns nun die Modellberechnungen anhand eines Beispiels an. Der Einfachheit halber berechnen wir hier ein Spam Filter Beispiel mit nur zwei Input-Variablen. Die beiden Variablen beschreiben, ob das Wort “afford” bzw. “price” in einer Email vorkommen oder nicht.
Frage
Berechnen wir als erstes die Priors. Der Trainingsdatensatz enthält insgesamt 4000 Emails. 1277 Emails sind Spam. Was sind die korrekten Priors?
TippLösung
\(p(y_i = 1) = 0.32\) und \(p(y_i = 0) = 0.68\).
Als nächstes rechnen wir die Randwahrscheinlichkeiten für die Spam Emails. In den 1277 Spam Emails enthalten 40 Emails das Wort “afford” und 223 Emails das Wort “price”.
Frage
Was sind die korrekten Randwahrscheinlichkeiten für die Spam Emails?
TippLösung
\(p(afford_i = 1 \mid y_i = 1) = 0.03\) und \(p(price_i = 1 \mid y_i = 1) = 0.17\).
Wichtig: die Wahrscheinlichkeit, dass das Wort “afford” bzw. “price” nicht vorkommt in einer Spam Email haben wir so indirekt auch bereits berechnet:
\[ p(afford_i = 0 \mid y_i = 1) = 1 - p(afford_i = 1 \mid y_i = 1) = 1 - 0.03 = 0.97 \]
\[ p(price_i = 0 \mid y_i = 1) = 1 - p(price_i = 1 \mid y_i = 1) = 1 - 0.17 = 0.83 \]
Als letztes rechnen wir nun noch die Randwahrscheinlichkeiten für die Ham Emails. In den 2723 Ham Emails enthalten 27 Emails das Wort “afford” und 134 Emails das Wort “price”.
Frage
Was sind die korrekten Randwahrscheinlichkeiten für die Ham Emails?
TippLösung
\(p(afford_i = 1 \mid y_i = 0) = 0.01\) und \(p(price_i = 1 \mid y_i = 0) = 0.05\).
Auch hier können die Wahrscheinlichkeiten für das “Gegenereignis” einfach gerechnet werden:
\[ p(afford_i = 0 \mid y_i = 0) = 1 - p(afford_i = 1 \mid y_i = 0) = 1 - 0.01 = 0.99 \]
\[ p(price_i = 0 \mid y_i = 0) = 1 - p(price_i = 1 \mid y_i = 0) = 1 - 0.05 = 0.95 \]
Nun wollen wir die Posterior Wahrscheinlichkeit berechnen, dass eine Email, welche sowohl das Wort “afford” als auch das Wort “price” enthält, eine Spam Email ist:
\[ \begin{split} p(y_i = 1 \mid afford_i = 1, price_i = 1) &= \frac{p(afford_i = 1 \mid y_i = 1) \cdot p(price_i = 1 \mid y_i = 1) \cdot p(y_i = 1)}{p(afford_i = 1, price_i = 1)}\\ &= \frac{0.03 \cdot 0.17 \cdot 0.32}{0.03 \cdot 0.17 \cdot 0.32 + 0.01 \cdot 0.05 \cdot 0.68}\\ &= \frac{0.001632}{0.001632 + 0.00034}\\ &= 0.83 \end{split} \]
Wow, gegeben, dass die beiden Worte “afford” und “price” in einer Email vorkommen, sind wir also ziemlich sicher, dass es sich um eine Spam Email handelt.
Frage
Rechnen Sie die Wahrscheinlichkeit, dass es sich bei einer Email um Spam handelt, wenn nur das Wort “afford” vorkommt, nicht aber das Wort “price”.
TippLösung
\[ \begin{split} p(y_i = 1 \mid afford_i = 1, price_i = 0) &= \frac{p(afford_i = 1 \mid y_i = 1) \cdot p(price_i = 0 \mid y_i = 1) \cdot p(y_i = 1)}{p(afford_i = 1, price_i = 0)}\\ &= \frac{0.03 \cdot 0.83 \cdot 0.32}{0.03 \cdot 0.83 \cdot 0.32 + 0.01 \cdot 0.95 \cdot 0.68}\\ &= \frac{0.007968}{0.007968 + 0.00646}\\ &= 0.55 \end{split} \]
Wir sind jetzt viel weniger sicher (55%), dass es sich um Spam handelt, da das Wort “price” nicht mehr in der Email vorkommt.
3.3 K-Nearest Neighbors
Mit dem K-Nearest-Neighbors (KNN) Modell schauen wir uns nun noch ein nicht-parametrisches Modell an. Solche Modelle sind nicht (oder zumindest nicht explizit) durch Parameter charakterisiert. Wir schauen uns zuerst ein einfaches Beispiel an.
Stellen Sie sich vor, Sie haben einen Datensatz mit 55 Produkten aus Ihrem Sortiment. Sie haben jedes dieser 55 Produkte auf Instagram und auf Tiktok durch Influencer*innen bewerben lassen. Für jedes der 55 Produkte hatten Sie ein Werbebudget für Instagram (\(x_{i1}\)) und ein Werbebudget für Tiktok (\(x_{i2}\)). Am Ende des Geschäftsjahrs haben Sie für jedes der 55 Produkte bestimmt, ob die Absatzziele erreicht wurden oder nicht (Output \(y_i\)). Die erfolgreichen Produkte (= Absatzziel erreicht) sind in untenstehender App als blaue Punkte eingezeichnet. Die roten Dreiecke repräsentieren die nicht-erfolgreichen Produkte. Sie sehen, dass erfolgreiche Produkte tendenziell höhere Instagram und Tiktok Werbebudgets aufwiesen als nicht-erfolgreiche Produkte. Sie möchten nun ein Modell schätzen, dass die Produkte automatisch klassifizieren kann. Dazu verwenden Sie das KNN Modell, das die \(K\) nächsten Nachbarn unter den 55 gegebenen Produkten sucht und dann die häufigste Beobachtung unter den \(K\) nächsten Nachbarn vorhersagt. In anderen Worten: wir suchen die \(K\) ähnlichsten Beobachtungen und nutzen diese, um eine Vorhersage zu machen. Die Grundidee ist also, dass ähnliche Beobachtungen (in Bezug auf die Input-Variablen) uns etwas über den Output einer neuen Beobachtung sagen.
Ausserdem können Sie in der ersten Abbildung auch den schwarzen Punkt mit der Maus setzen, wodurch Ihnen die \(K\) nächsten Punkte des schwarzen Punkts angezeigt werden.
Die zweite Abbildung zeigt die Entscheidungsregionen mit unterschiedlicher Intensität je nachdem wie sicher sich das Modell ist. In einer Region, in der alle \(K\) Nachbarn nicht-erfolgreiche Produkte sind, sind wir uns eher sicher bezüglich der Vorhersage als in einer Region, in der die Anteile zwischen erfolgreichen und nicht-erfolgreichen Produkten ausgeglichen sind.
Fragen
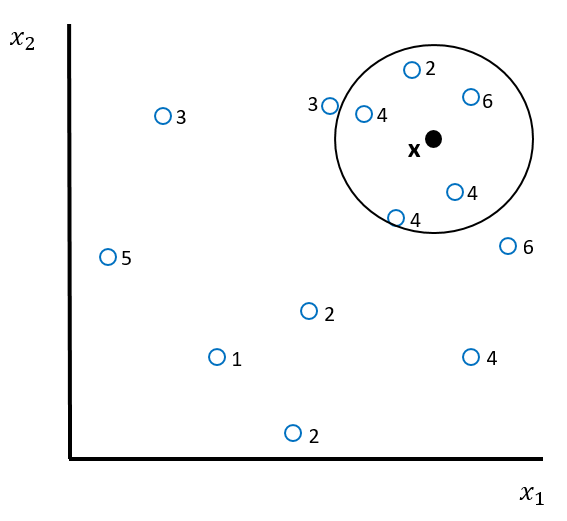
Stellen Sie sich vor, Sie haben folgendes Klassifikationsproblem, das Sie mit KNN lösen wollen. Welche Kategorie prognostiziert ein KNN Modell für den Punkt \(x\) in der unten stehenden Abbildung?
- Blauer Kreis.
- Beide Klassen sind gleich wahrscheinlich.
- Rotes Kreuz.
TippLösung
Es hat drei rote Kreuze und zwei blaue Kreise in der Nachbarschaft. Die roten Kreuze sind darum in der Mehrheit, weshalb Antwort c korrekt ist.
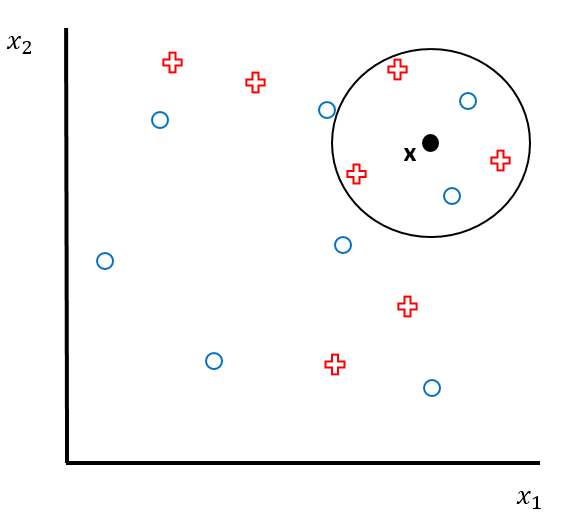
Was ist der Wert für \(K\) für das KNN Modell in der oben stehenden Abbildung?
- 5
- 2
- 3
- 10
TippLösung
Die Nachbarschaft, dargestellt durch den Kreis, enthält 5 Beobachtungen. Deshalb ist Antwort a korrekt.
Stellen Sie sich vor, Sie haben folgendes Regressionsproblem, das Sie mit KNN lösen wollen. Was ist die Vorhersage für den Punkt \(x\) für das KNN-Regressionsmodell in der unten stehenden Abbildung? Die Zahlen neben den Datenpunkten stellen die entsprechenden \(y_i\)-Werte dar.
- 4
- 20
- 5
TippLösung
Der Durchschnitt über die 5 \(y_i\)-Werte in der Nachbarschaft beträgt 4, weshalb Antwort a korrekt ist.
3.3.1 Hyperparameter \(K\)
Selbstverständlich spielt der konkrete Wert von \(K\) hier eine grosse Rolle - sollen wir nur \(K=1\) Nachbarn berücksichtigen? Oder \(K=10\) Nachbarn? Die erste Abbildung in der App zeigt nicht nur die 55 Datenpunkte, sondern auch die Decision Boundary (in schwarz). Untersuchen Sie kurz, wie sich diese Entscheidungsgrenze verändert, wenn Sie \(K\) erhöhen oder reduzieren.
Die Decision Boundary variert stark jenachdem welchen Wert Sie für \(K\) wählen. Je grösser \(K\), desto glätter wird die Decision Boundary.
Sie haben zudem sicherlich bemerkt, dass die Decision Boundary klar nicht-linear ist. Das Modell gilt darum auch als hoch-flexibles Modell.
Frage
Was passiert, wenn Sie \(K=n\) setzen (\(n\) ist die Grösse des Trainingsdatensatzes)?
TippLösung
Wenn \(K=n\), dann wird für jede neue Beobachtung der ganze Trainingsdatensatz als nächste Nachbarn verwendet. Im Klassifikationsfall führt das dazu, dass für jede neue Beobachtung immer die Kategorie in \(y\), die am häufigsten vorkommt, vorhergesagt wird.
Im Regressionsfall würde für jede neue Beobachtung immer der Durchschnitt der Outputwerte im Trainingsdatensatz, also \(\bar{y}\), vorhergesagt werden.
Doch wie wählen wir einen guten Wert für den Hyperparameter \(K\)? Genau gleich wie für \(\lambda\) bei der regularisierten (logistischen) Regression wählen wir \(K\) mittels Resampling (mehr dazu in Kapitel 4).
3.3.2 Distanzen messen
Um die \(K\) nächsten Nachbarn zu finden, müssen wir die Distanzen zwischen Punkten rechnen können. Dazu verwenden wir (im einfachsten Fall, wenn alle Input-Variablen numerischer Natur sind) die Euklidische Distanz.
Die Euklidische Distanz zwischen zwei Vektoren \(\mathbf{x}_i = \begin{pmatrix} x_{i1} & x_{i2} \end{pmatrix}'\) und \(\mathbf{z}_i = \begin{pmatrix} z_{i1} & z_{i2} \end{pmatrix}'\) lässt sich wie folgt berechnen:
\[ d(\mathbf{x}_i, \mathbf{z}_i) = \sqrt{(x_{i1} - z_{i1})^2 + (x_{i2} - z_{i2})^2} \]
Haben Ihre Vektoren mehr als zwei Dimensionen, dann kommen einfach weitere quadrierte Terme dazu, z.B. \((x_{i3} - z_{i3})^2\). Im zweidimensionalen Raum kann die Berechnung der Euklidischen Distanz direkt mit dem Satz von Pythagoras nachvollzogen werden.
3.3.3 Fluch der Dimensionalität
Sie konnten sich vielleicht in der Zwischenzeit sehr begeistern für das KNN Modell, weil es einerseits so einfach ist und andererseits trotzdem sehr komplexe, nicht-lineare Regressions- oder Klassifikationsprobleme lösen kann.
Was etwas weniger offensichtlich ist: das Modell macht keine Annahmen über die Form oder Verteilung der Trainingsdaten. Wir machen beispielsweise nicht wie oben bei Naive Bayes die Annahme, dass eine numerische Input-Variable normalverteilt ist. Ausserdem: wenn Sie über sehr, sehr viele Trainingsdaten verfügen, dann gibt es gewisse mathematische Garantien, dass KNN sehr nahe an das bestmögliche Modell herankommt, d.h., dass unser \(\hat{f}(\mathbf{x}_i)\) sehr nahe beim unbekannten \(f(\mathbf{x}_i)\) liegt.
Warum wird KNN in der Praxis trotzdem nicht allzu häufig verwendet? Weil es stark am sogenannten Fluch der Dimensionalität (engl. Curse of Dimensionality) leidet.
Doch was bedeutet das? Je mehr Input-Variablen wir haben, desto weiter entfernt sind Datenpunkte voneinander (das ist etwas, das man sich nur schwer vorstellen kann, aber Sie können es mir für den Moment einfach mal glauben). Das KNN beruht auf der Grundidee, dass wir \(K\) nahe, ähnliche Beobachtungen für die Vorhersage verwenden. Wenn diese \(K\) nahen Beobachtungen im hochdimensionalen Raum (= viele Input-Variablen) nicht mehr nahe sind, dann funktioniert auch das Modell nicht mehr gut.
Wir machen hier ein einfaches Beispiel, das Ihnen dabei helfen soll, den Fluch der Dimensionalität intuitiv besser zu verstehen. Das Beispiel ist inspiriert durch (Ananthaswamy 2024, Kap. 5). Stellen Sie sich vor, wir haben nur binäre Input-Variablen, die entweder den Wert 0 oder 1 haben können. Ausserdem haben wir einen Trainingsdatensatz von \(n=50\) Beobachtungen.
- Im ersten Fall haben wir nur eine binäre Input-Variable \(x_{i1}\) (illustriert ganz links in folgender Abbildung). Wir nehmen nun an, dass die Werte dieser Variable zufällig entweder 0 oder 1 sind, also je eine 50% Wahrscheinlichkeit haben 0 oder 1 zu sein. Wir erwarten darum, dass wir im Schnitt \(n \cdot p = 50 \cdot 0.5 = 25\)7 Beobachtungen mit dem Wert 0 und 25 Beobachtungen mit dem Wert 1 haben.
- Im zweiten Fall haben wir zwei binäre Input-Variablen \(x_{i1}\) und \(x_{i2}\). Auch hier nehmen die Variablen die Werte 0 und 1 rein zufällig an. Nun haben wir aber vier mögliche Kombinationen von Input-Variablenwerten (mittlere Abbildung). Jede der Kombinationen hat eine Wahrscheinlichkeit von 0.25. Wir erwarten darum für jede mögliche Kombination \(n \cdot p = 50 \cdot 0.25 = 12.5\) Beobachtungen.
- Im Fall von drei binären Input-Variablen haben wir acht mögliche Kombinationen von \(x_{i1}\), \(x_{i2}\) und \(x_{i3}\) (rechte Abbildung). Dadurch erwarten für jede mögliche Kombination nur noch \(n \cdot p = 50 \cdot 0.125 = 6.25\) Beobachtungen.
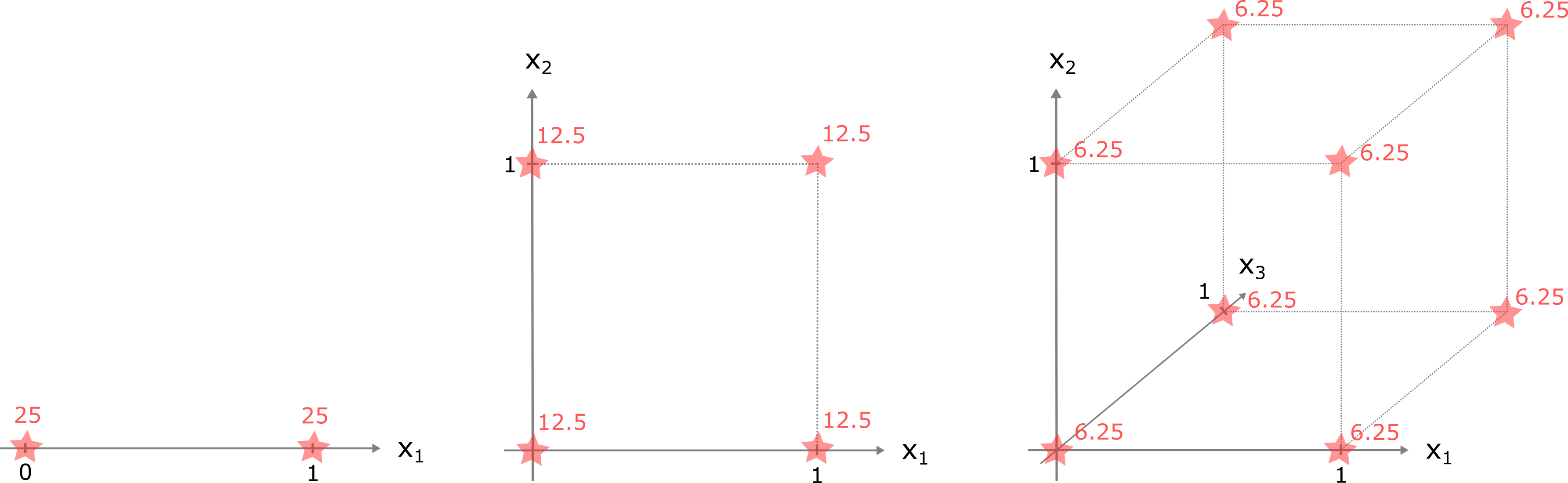
Allgemein gilt: im Fall von \(p\) binären Input-Variablen, gibt es \(2^p\) mögliche Kombinationen der Input-Variablenwerte und dementsprechend erwarten wir für jede Kombination \(n \cdot (1/2^p)\) Beobachtungen. Für \(p=10\) können wir beispielsweise für jede mögliche Kombination nur noch 0.05 Beobachtungen erwarten. Sie sehen vielleicht schon das Problem. Mit einer gegebenen Anzahl Trainingsbeobachtungen \(n\) reduziert sich die Anzahl Beobachtungen, die “nahe” beieinander liegen immer mehr, je grösser die Anzahl Input-Variablen \(p\).
3.4 Klassifikation in R
Wir schauen uns ähnlich wie bei der Regression zuerst kurz an, wie man mit Base R ein logistisches Regressionsmodell berechnet. In einem zweiten Schritt schauen wir uns minimale Beispiele für die logistische Regression, Naive Bayes und das KNN Modell im tidymodels Framework an.
3.4.1 Base R
In Base R lassen sich logistische Regressionsmodelle mit der glm() Funktion (glm steht für generalized linear model) rechnen.
Wir wenden die Funktion hier für unser simples Beispiel von ganz oben mit \(n=5\) Beobachtungen an:
# Datenpunkte
x <- c(-4.1, 0.5, -0.1, 1.4, 4.4)
y <- c(0, 0, 1, 1, 1)
# Dataframe
df <- data.frame(x = x, y = y)
# Modellrechnung
mod <- glm(y ~ x, data = df, family = "binomial")
# Modelloutput
summary(mod)
Call:
glm(formula = y ~ x, family = "binomial", data = df)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.1496 1.3198 0.113 0.910
x 0.9901 1.1371 0.871 0.384
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 6.7301 on 4 degrees of freedom
Residual deviance: 3.9211 on 3 degrees of freedom
AIC: 7.9211
Number of Fisher Scoring iterations: 6Wir sehen im Output in der Spalte Estimate die trainierten Gewichte \(w_0\) und \(w_1\). Alles andere in diesem Output interessiert uns aus einer ML-Sicht eher weniger.
Um Vorhersagen zu rechnen, können wir folgenden Code verwenden (hier für neue Input-Werte von 0.5 und 5.1). Mit type = "response" stellen wir sicher, dass das Modell vorhergesagte Wahrscheinlichkeiten zurück gibt.
# Modellvorhersagen
yp <- predict(mod, newdata = data.frame(x = c(0.5, 5.1)), type = "response")
yp 1 2
0.6557965 0.9945090 3.4.2 tidymodels
Sobald wir regularisierte logistische Regressionsmodelle oder eben Naive Bayes oder KNN rechnen wollen, eignet sich der tidymodels Framework besser als Base R.
Für das logistische Modell verwenden wir als Engine wie bei der Regression das glmnet Package. Für Naive Bayes verwenden wir als Engines naivebayes und discrim und für KNN das kknn Package. All diese Packages müssen zusammen mit tidymodels erstmal geladen werden:
library(tidymodels)
library(naivebayes)
library(discrim)
library(glmnet)
library(kknn)Der folgende Code-Block generiert das Datenbeispiel von oben mit den zwei Input-Variablen (die Details sind hier nicht so wichtig):
# Wir werden Daten aus einer multivariate Normalverteilung samplen,
# wozu wir das MASS R-Package verwenden.
library(MASS)
# Seed für Reproduzierbarkeit
set.seed(2)
# Anzahl Beobachtungen
n <- 50
# Hier definieren wir die Kovarianzmatrizen der beiden multivariaten Normalvert.
Sigma0 <- matrix(c(1, 0, 0, 1.5), nrow = 2, ncol = 2)
Sigma1 <- matrix(c(1, 0.5, 0.5, 1), nrow = 2, ncol = 2)
# Hier ziehen wir die Input-Variablenwerte für die Beob. der
# ersten und der zweiten Kategorie.
class0 <- mvrnorm(n/2, mu = c(4, 4), Sigma0)
class1 <- mvrnorm(n/2, mu = c(6, 6), Sigma1)
# Wir kombinieren die Input-Variablenwerte der beiden Kategorien zu einem DF.
df <- data.frame(rbind(class0, class1))
# Wir fügen die Outputwerte hinzu.
df$y <- c(rep(0, n/2), rep(1, n/2))
# Schauen wir uns die ersten paar Zeilen an:
head(df) X1 X2 y
1 6.451706 2.901509 0
2 3.522763 4.226393 0
3 4.596558 5.944705 0
4 3.207797 2.615578 0
5 3.710363 3.901712 0
6 3.261061 4.162181 0Bevor wir beginnen, schreiben wir nun kurz eine Funktion, die uns jeweils die Decision Boundary eines Modells visualisieren wird (auch hier sind die genauen Details im Code weniger wichtig):
plot_db <- function(data, fit) {
# Grösse der Trainingsdaten
n <- nrow(data)
# Definiere die Farbe für die Datenpunkte.
cols <- c(rep(rgb(1, 0, 0, 0.4), n/2), rep(rgb(0, 0, 1, 0.4), n/2))
# Nun erstellen wir Sequenzen von möglichen X1 und X2 Werten.
x1 <- seq(0, 10, len = 300); x2 <- seq(0, 10, len = 300)
# Nun kombinieren wir alle möglichen X1 und X2 Werte (300 * 300 = 90'000)
grid <- expand.grid(X1 = x1, X2 = x2)
# z ist eine Matrix, die alle Vorhersagen für die Kombinationen im Grid enthält.
z <- matrix(predict(fit, grid, type = "prob")$.pred_1, nrow = 300, byrow = TRUE)
# Plot Parameter
par(mar = c(4, 5, 0.5, 0.5), oma = c(0.5, 0.5, 0.5, 0.5), pty = "s")
# Leerer Plot
plot(1, 1,
axes = F, ylim = c(0, 10), xlim = c(0, 10),
xlab = "X2", ylab = "X1",
type = "n", xaxs = "i", yaxs = "i",
cex = 2, cex.lab = 1.5, cex.axis = 1.5)
# Box um den Plot und Achsen
box(lwd = 1)
axis(side = 1, at = seq(0, 10, 2), labels = seq(0, 10, 2), cex.axis = 1.5)
axis(side = 2, at = seq(0, 10, 2), labels = seq(0, 10, 2), cex.axis = 1.5)
# Schattierte Flächen (basierend auf Matrix z)
image(x2, x1, z, col = c(rgb(1,0,0,.1), rgb(0,0,1,.1)), breaks = c(0, .5, 1), add = TRUE)
# Decision Boundary (basierend auf Matrix z)
contour(x2, x1, z, levels = .5, add = TRUE, drawlabels = FALSE, lwd = 2, col = "grey")
# Datenpunkte hinzufügen
points(data$X2, data$X1, pch = 16, cex = 2, col = cols)
}Logistische Regression
Das regularisierte logistische Regressionsmodell funktioniert sehr ähnlich wie im Regressionsfall. Bei der Modellspezifikation verwenden wir jedoch logistic_reg() anstelle von linear_reg().
# Modellspezifikation für lineares Modell mit Regularisierung
lr_mod <-
logistic_reg(penalty = 0.005, mixture = 1) |>
set_engine("glmnet")Nun fitten wir das Modell mit fit(). Für das formula Objekt gibt es folgende Besonderheiten:
- Die Zielvariable ist im Klassifikationsfall kategorischer Natur, weshalb
tidymodelshier einen Faktor erwartet. - Wir experimentieren hier etwas weiter mit polynomischen Input-Variablen und nehmen neben \(x_{i1}\) und \(x_{i2}\) auch \(x_{i1}^2, x_{i2}^2\) und \(x_{i1} \cdot x_{i2}\) als zusätzliche Input-Variablen ins Modell. Damit wir nicht Overfitting betreiben, ist Regularisierung hier besonders wichtig. Wir können die zusätzlichen Input-Variablen mit der Helper-Funktion
I()einfügen.
# Modelltraining
lr_fit <-
lr_mod |>
fit(formula = factor(y) ~ X1 + X2 + I(X1^2) + I(X2^2) + I(X1 * X2), data = df)Schauen wir uns das trainierte Modell am besten kurz an:
# Trainierte Parameter des Modells
tidy(lr_fit) %>%
print(n = 6)# A tibble: 6 × 3
term estimate penalty
<chr> <dbl> <dbl>
1 (Intercept) -5.50 0.005
2 X1 0 0.005
3 X2 0 0.005
4 I(X1^2) 0.0291 0.005
5 I(X2^2) 0 0.005
6 I(X1 * X2) 0.185 0.005Um zu sehen, welcher Decision Boundary dieses Modell entspricht, können wir sie visualisieren.
# Decision Boundary visualisieren
plot_db(df, lr_fit)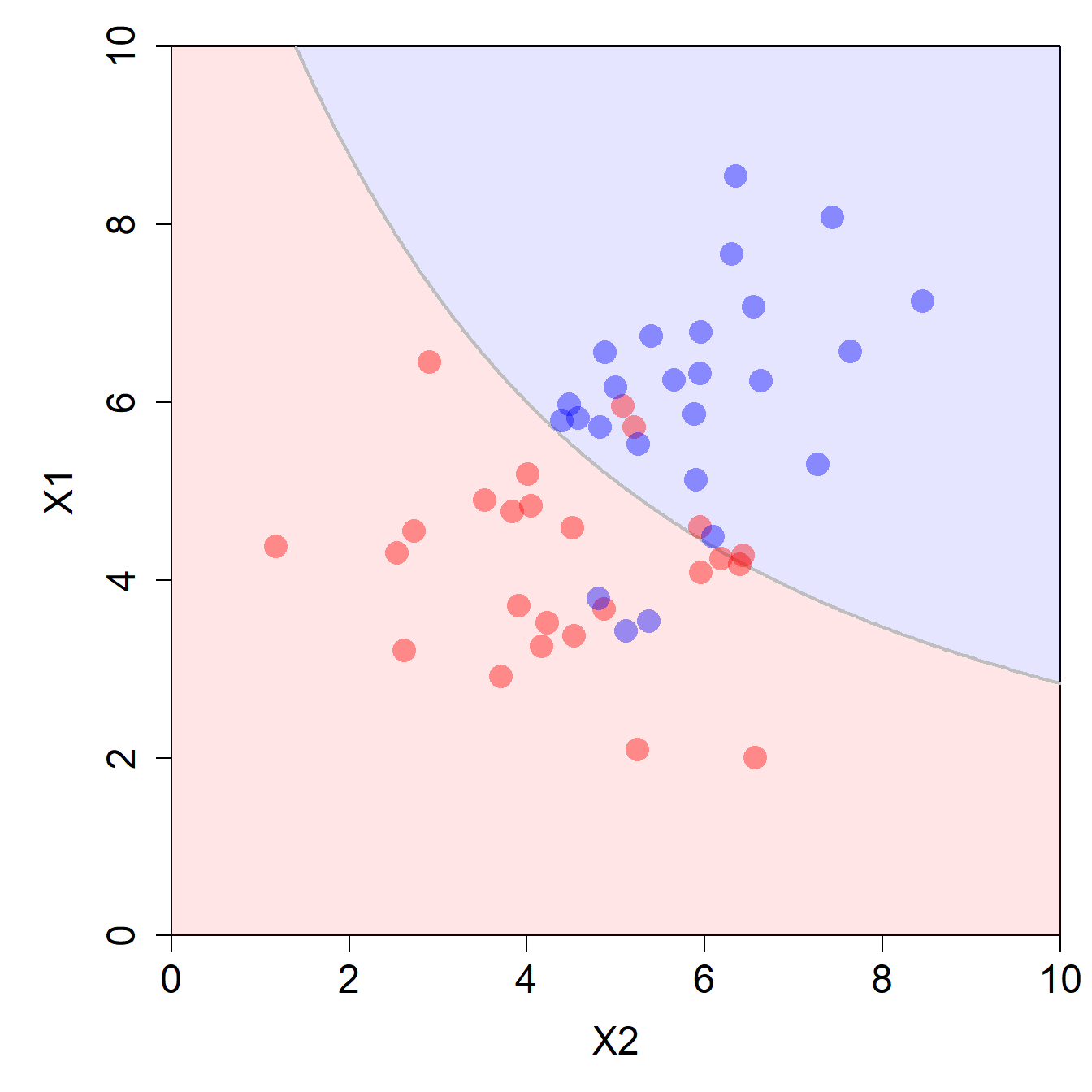
Wir haben das Modell hier mit \(\lambda=0.005\) regularisiert. Sie können gerne lokal weiter experimentieren und andere Werte für den Regularisierungsparameter ausprobieren. Wir werden später sehen, dass wir den optimalen Wert für \(\lambda\) (bzw. penalty) via Resampling (Cross-Validation) tunen können.
Naive Bayes
Das Naive Bayes Modell wird mit naive_Bayes() spezifiziert. Wir setzen das Argument Laplace = 1.0, doch was macht dieses Argument genau? Wir haben gesehen, dass wir für Naive Bayes viele Randwahrscheinlichkeiten aus den Daten schätzen müssen. Doch was passiert, wenn z.B. keine einzige Spam Email das Wort “write” enthält? In dem Fall ist die Wahrscheinlichkeit \(p(write_i \mid y_i=1) = 0\). Wenn jetzt also eine neue Spam Email, welche das Wort “write” enthält, in Ihr Postfach reinkommt, dann wird der Spam Filter eine Spam Wahrscheinlichkeit von 0 berechnen. Mit Laplace = 1.0 beheben wir dieses Problem, indem wir bei der Schätzung der Randwahrscheinlichkeiten überall eine 1 addieren, so dass jedes Wort im schlimmsten Fall eine minimale Wahrscheinlichkeit aufweist, in einer Email (Spam oder Ham) vorzukommen.
Mit usekernel = FALSE stellen wir sicher, dass wie oben Normalverteilungen geschätzt werden.
# Modellspezifikation
nb_mod <-
naive_Bayes(Laplace = 1.0) %>%
set_engine("naivebayes", usekernel = FALSE)Der Fit des Modells ist wie oben bei der logistischen Regression (wir verzichten hier jedoch auf die zusätzlichen Input-Variablen).
# Model Fitting Naive Bayes
nb_fit <-
nb_mod %>%
fit(formula = factor(y) ~ X1 + X2, data = df)
# Ausgabe des Modells
nb_fitparsnip model object
================================= Naive Bayes ==================================
Call:
naive_bayes.default(x = maybe_data_frame(x), y = y, laplace = ~1,
usekernel = ~FALSE)
--------------------------------------------------------------------------------
Laplace smoothing: 1
--------------------------------------------------------------------------------
A priori probabilities:
0 1
0.5 0.5
--------------------------------------------------------------------------------
Tables:
--------------------------------------------------------------------------------
:: X1 (Gaussian)
--------------------------------------------------------------------------------
X1 0 1
mean 4.195698 6.026455
sd 1.072403 1.285003
--------------------------------------------------------------------------------
:: X2 (Gaussian)
--------------------------------------------------------------------------------
X2 0 1
mean 4.409033 5.841578
sd 1.401447 1.059517
--------------------------------------------------------------------------------Wir sehen im obigen Output sowohl die Priors (beide Kategorien kommen genau gleich häufig vor) als auch die geschätzten Parameter der Normalverteilungen (gegeben die Kategorien in \(y\)) für die beiden Input-Variablen.
Für einen neuen Datenpunkt (4, 6) würden wir eher die Kategorie 0 vorhersagen, da sie eine klar höhere Wahrscheinlichkeit (0.621) hat als die Kategorie 1 (0.379).
# Vorhersage für einen neuen Datenpunkt
predict(nb_fit, new_data = data.frame(X1 = 4, X2 = 6), type = "prob")# A tibble: 1 × 2
.pred_0 .pred_1
<dbl> <dbl>
1 0.621 0.379Und schliesslich können wir auch hier die Decision Boundary visualisieren und sehen, dass wir hier kein lineares Modell mehr vorfinden!
# Decision Boundary visualisieren
plot_db(df, nb_fit)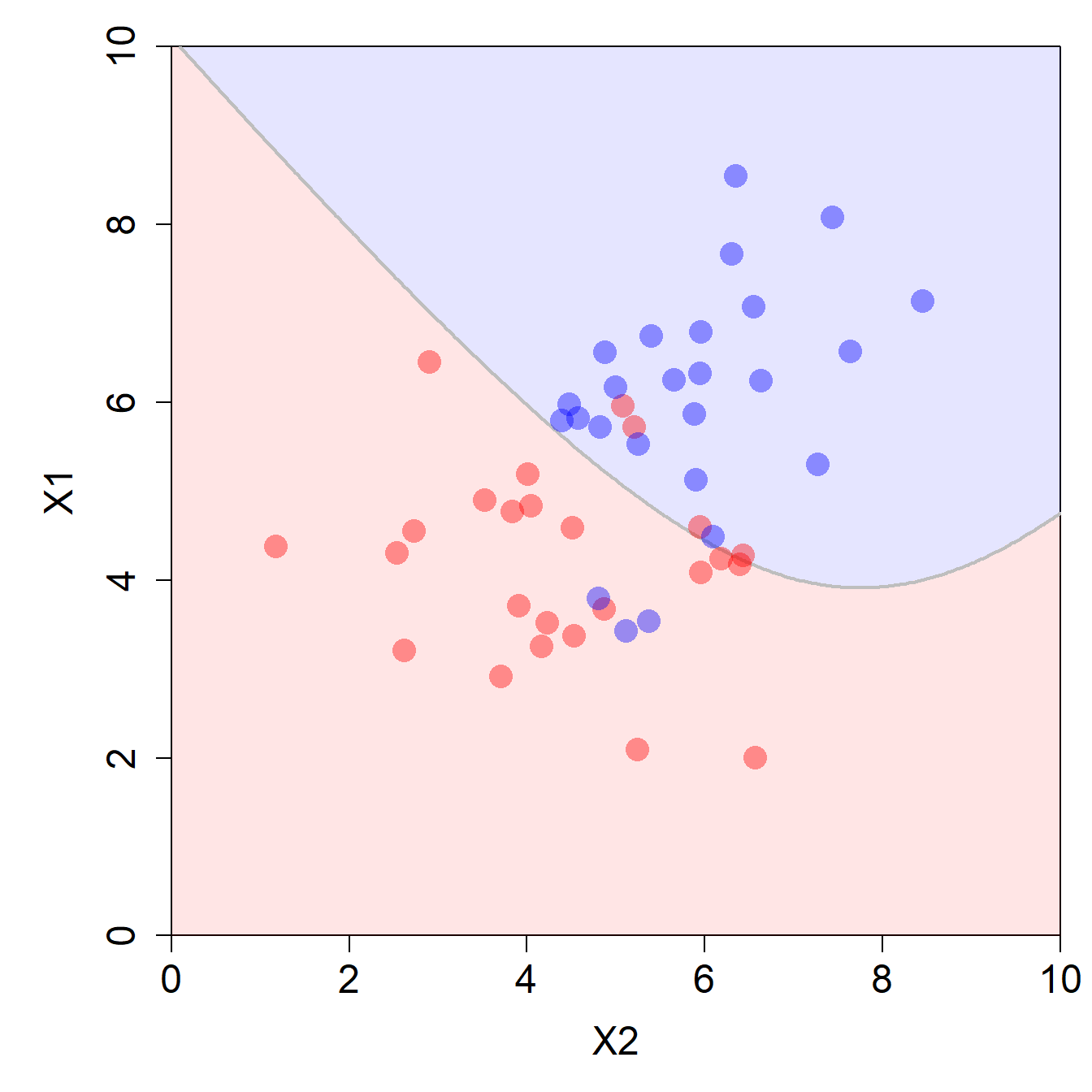
K-Nearest Neighbors
Zum Abschluss fitten wir noch ein KNN Modell mit \(K=5\) Nachbarn. Da dieses Modell wie erwähnt auf den Regressions- und den Klassifikationsfall anwendbar ist, setzen wir mit set_mode() den gewünschten Fall.
# Modellspezifikation
knn_mod <-
nearest_neighbor(neighbors = 5) |>
set_mode("classification") |>
set_engine("kknn")Nun kann das Modell trainiert werden:
# Model Fitting KNN
knn_fit <-
knn_mod %>%
fit(formula = factor(y) ~ X1 + X2, data = df)Auch hier machen wir eine Vorhersage für den Datenpunkt (4, 6) und auch KNN kommt zum Schluss, dass die Kategorie 0 wahrscheinlicher ist.
# Vorhersage für einen neuen Datenpunkt
predict(knn_fit, new_data = data.frame(X1 = 4, X2 = 6), type = "prob")# A tibble: 1 × 2
.pred_0 .pred_1
<dbl> <dbl>
1 0.88 0.12Die Decision Boundary ist hier schon erheblich komplexer und zeigt klare Anzeichen von Overfitting. Man müsste den Hyperparameter \(K\) etwas erhöhen! Auch hier gilt: der optimale Wert für \(K\) kann mittels eines Hyperparamter Tunings (Resampling) gefunden werden (mehr dazu in Kapitel 4).
# Decision Boundary visualisieren
plot_db(df, knn_fit)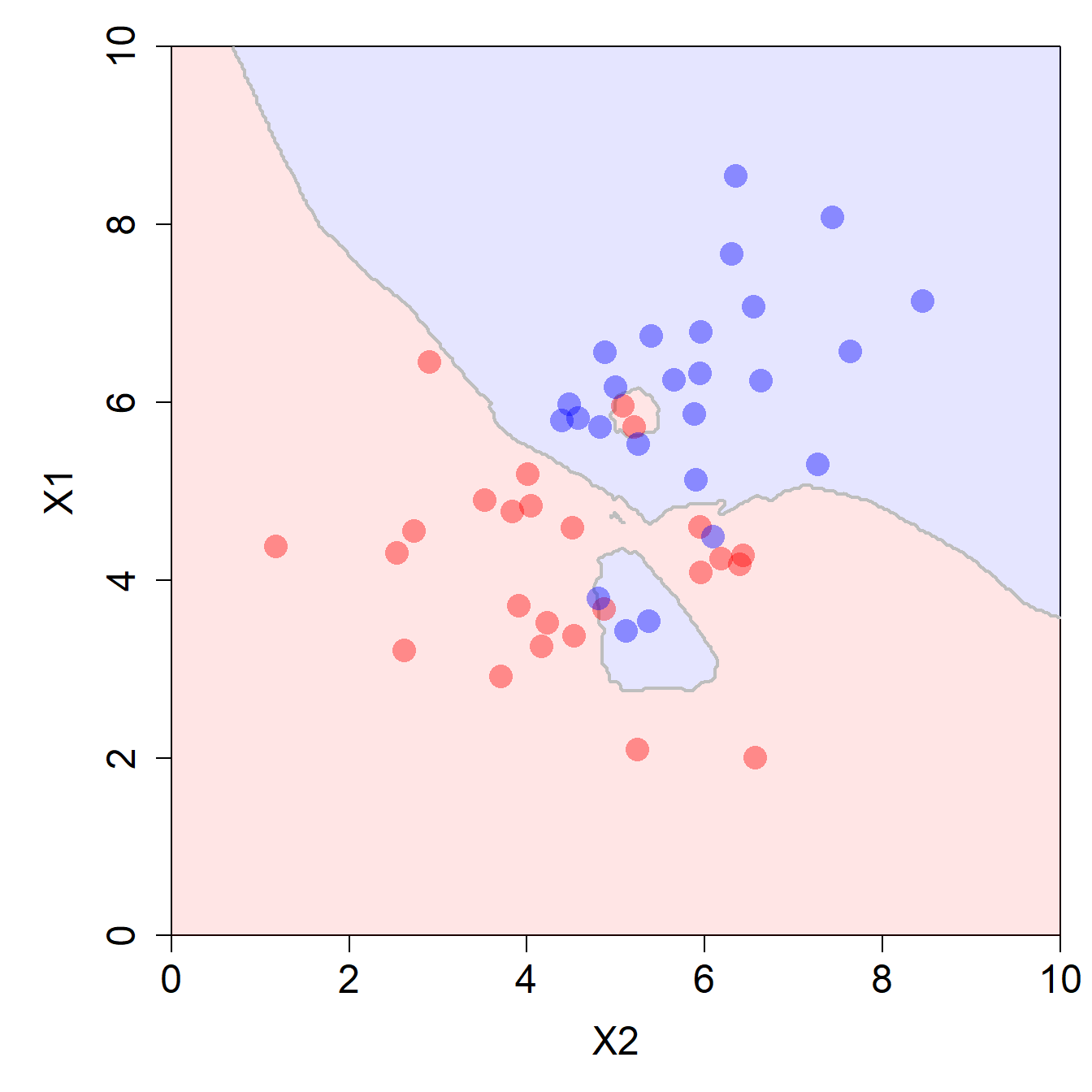
Manchmal wird die Kategorie 1 auch mit “Erfolg” und die Kategorie 0 mit Misserfolg betitelt. Diese Bezeichnungen sind jedoch etwas irreführend. Versucht man vorherzusagen, ob jemand eine Krankheit hat, dann ist “krank” meist die Kategorie 1. Dieses Ereignis kann kaum als “Erfolg” gewertet werden. Im Prinzip ist es Ihnen überlassen, wie Sie die beiden möglichen Kategorien mit 0/1 kodieren. Meist wird Kategorie 1 für das uns primär interessierende Ereignis gesetzt: z.B. Krankheit, Lehrabbruch, Kreditkartenbetrug.↩︎
Auch hier einmal mehr im ML eine irreführende Namensgebung: das logistische Regressionsmodell ist ein Klassifikationsmodell.↩︎
Das heisst, die Modelle haben das Ziel einen numerischen (reellen) Wert zwischen 0 und 1 zurückzugeben.↩︎
Wir haben bei der Sigmoid Funktion gesehen, dass sie immer beim Wert \(z=0\) den Wert 0.5 annimmt. Es ist hier wichtig zu sehen, dass wir auf der x-Achse die Input-Variable \(x\) darstellen und nicht \(z\). Hier, im Fall der logistischen Regression, gilt \(z=w_0 + w_1 \cdot x\). Indem wir \(z\) gleich 0 setzen und nach \(x\) auflösen, finden wir, dass \(x=-w_0/w_1\) oder in unserem konkreten Beispiel \(x = -(0.15/0.99) \approx -0.15\).↩︎
Wir verwenden hier den bekannten Schätzer für den Parameter \(\mu\) der Normalverteilung, nämlich \(\bar{x} = \frac{1}{n} \sum_i^n x_i\).↩︎
Wir verwenden hier den bekannten Schätzer für die Varianz \(\sigma^2\) der Normalverteilung, nämlich \(\hat{\sigma}^2 = \frac{1}{n} \sum_i^n (x_i - \bar{x})^2\).↩︎
Diese Berechnung ist nichts anderes als der Erwartungswert einer Binomialverteilung.↩︎