2 Lineare Regression
In diesem Kapitel werden wir uns eingehend mit dem einfachsten Modell für das Regressionsproblem auseinander setzen, nämlich dem linearen Regressionsmodell. Liegt ein Regressionsproblem vor, dann macht es in der Praxis fast immer Sinn mit diesem Modell zu starten und dann die Komplexität nach Bedarf zu erhöhen.
2.1 ML-Modelle im Allgemeinen
Wie bereits in Kapitel 1 gesehen, geht es beim Regressionsproblem darum, eine stetige Variable \(y_i \in \mathbb{R}\) möglichst optimal vorherzusagen. Dazu verwenden wir eine oder mehrere Input-Variablen, welche wir kompakt als Vektor \(\mathbf{x}_i\) schreiben.
Das Problem ist nur sinnvoll lösbar, falls es tatsächlich einen Zusammenhang zwischen den Input-Variablen \(\mathbf{x}_i\) und dem Output \(y_i\) gibt, wenn wir also aus \(\mathbf{x}_i\) etwas über \(y_i\) lernen können. Wir nehmen ganz allgemein an, dass der Zusammenhang zwischen dem Output \(y_i\) und den Input-Variablen \(\mathbf{x}_i\) mathematisch wie folgt ausgedrückt werden kann (James u. a. 2021, Kap. 2):
\[ y_i = f(\mathbf{x}_i) + \epsilon \]
- Die Funktion \(f(\mathbf{x}_i)\) bezeichnet die systematische Information, die wir aus \(\mathbf{x}_i\) im Hinblick auf \(y_i\) lernen können. Oder in anderen Worten: \(f\) mappt die Input-Werte \(\mathbf{x}_i\) auf die Output-Werte \(y_i\).
- \(\epsilon\) ist ein Fehlerterm, der die Differenz zwischen \(y_i\) und \(f(\mathbf{x}_i)\) abbildet,1 also den nicht-lernbaren (unsystematischen) Teil. Der Fehlerterm beinhaltet einerseits den Effekt von Variablen, die uns nicht zur Verfügung stehen, aber einen Einfluss auf den Output \(y_i\) haben und andererseits nicht-messbare Variation in \(y_i\), oft auch einfach Noise genannt. Grob gesagt: alles nicht-messbare. Auch wichtig zu sehen: der Fehler ist additiv, wir addieren ihn zum lernbaren Teil hinzu.
Der Output \(y_i\) ergibt sich also aus der Addition des systematischen Teils \(f(\mathbf{x}_i)\) sowie des Fehlerterms \(\epsilon\).
HinweisZiel des Machine Learnings
Ziel des Machine Learnings ist es, eine Funktion \(\hat{f}(\mathbf{x}_i)\) zu trainieren (schätzen), die der wahren aber unbekannten Funktion \(f(\mathbf{x}_i)\) so nahe wie möglich kommt. Im (unrealistischen) Idealfall ist unser trainiertes Modell gleich der wahren Funktion, also \(\hat{f}(\mathbf{x}_i) = f(\mathbf{x}_i)\) und wir haben die systematische Information perfekt gelernt.
Sobald wir \(\hat{f}(\mathbf{x}_i)\) trainiert haben, können wir damit Vorhersagen machen, denn die Vorhersage für eine neue Beobachtung \(\mathbf{x}_0\) ist nichts anderes als der Wert der trainierten Funktion an diesem Punkt, also \(\hat{y}_0 = \hat{f}(\mathbf{x}_0)\).
Jedes ML-Modell, das wir uns in diesem Buch anschauen werden, kann als eine mathematische Funktion \(\hat{f}(\mathbf{x}_i)\) der Input-Variablen \(\mathbf{x}_i\) aufgeschrieben werden.
2.2 Das Modell (ausgeschrieben)
Nun wollen wir uns konkret mit dem linearen Regressionsmodell befassen. Das bedeutet nun nichts anderes, als dass wir die allgemein geschriebene Funktion \(f(\mathbf{x}_i)\) durch eine konkrete mathematische Funktion ersetzen. Im Machine Learning ist das der erste wichtige Schritt, nämlich die Modellwahl (engl. Model Selection). Das Modell kann wie folgt geschrieben werden:
\[ f(\mathbf{x}_i) = w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip} \] Wir verzichten hier bewusst darauf, den Hut für \(f\) zu schreiben, da es sich lediglich um eine allgemein gültige Funktion handelt und noch nichts geschätzt bzw. trainiert wurde. Dieses Modell bzw. diese Funktion hat sogenannte Parameter, die es zu schätzen gilt. Es handelt sich also auch hier um ein parametrisches Modell. Hier sind dies die Parameter \(w_0,\; w_1,\; \ldots,\; w_p\). Wegen der Konstante \(w_0\) haben wir immer einen Parameter mehr als es Input-Variablen hat, also \(p+1\) Parameter.
Diese Parameter sind die Schlüsselzutat in einem ML-Modell. Wir wollen sie optimieren, so dass die trainierte Funktion \(\hat{f}(\mathbf{x}_i)\) der wahren Funktion \(f(\mathbf{x}_i)\) möglichst nahe kommt und die beobachteten Daten möglichst gut beschreibt.
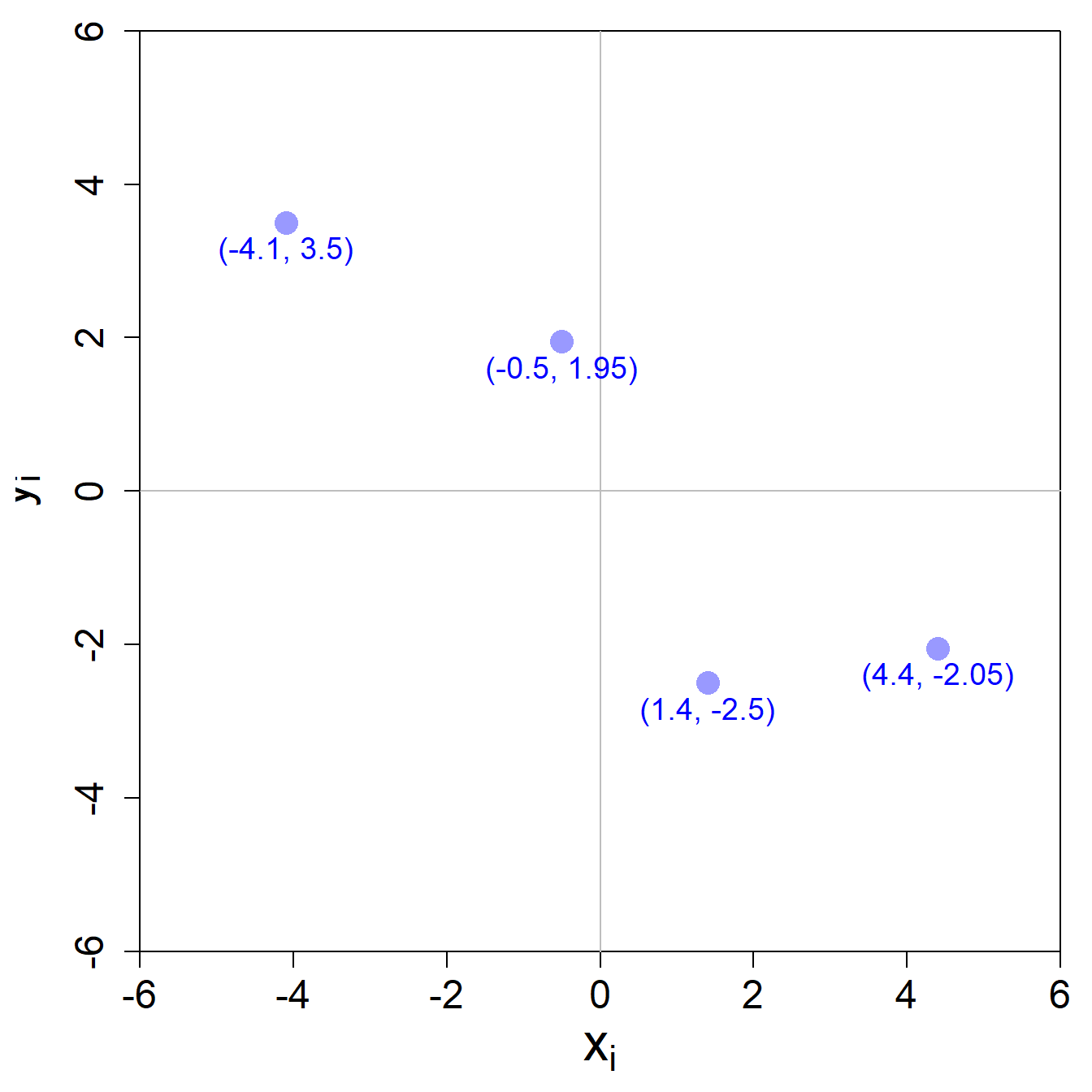
Wir schauen uns in diesem Kapitel ein ganz einfaches Beispiel mit nur einer Input-Variable \(x_i\) an, so dass der Zusammenhang zwischen dem Output \(y_i\) und dem Input \(x_i\) in 2D dargestellt werden kann. In diesem Zusammenhang spricht man vom einfachen linearen Regressionsmodell. Ausserdem haben wir nur vier Beobachtungen, welche in folgender Abbildung in einem Streudiagramm dargestellt werden:
Obwohl obige Abbildung ähnlich aussieht wie die Abbildungen zum Perceptron, gibt es hier einen bedeutenden Unterschied. Auf der y-Achse des Streudiagramm wird der Outputwert der Beobachtungen dargestellt, während auf der x-Achse der Input-Wert angezeigt wird. Es wird nun darum gehen, eine Gerade zu finden, welche die vier Beobachtungen bestmöglich repräsentiert.
2.3 Das Modell (kompakt)
Sie haben oben gesehen, dass es ziemlich umständlich sein kann, das lineare Regressionsmodell aufzuschreiben, insbesondere wenn wir viele Input-Variablen haben. Mithilfe von Vektoren und Matrizen können wir das Modell viel kompakter aufschreiben.
Wir haben in Kapitel 1 bereits gesehen, dass die Input-Variablen für eine Beobachtung \(i\) als Spaltenvektor geschrieben werden können. Wir modifizieren diesen Spaltenvektor in einem ersten Schritt, indem wir an erster Stelle eine 1 einfügen,2 also:
\[\mathbf{x}_i=\begin{pmatrix} 1\\ x_{i1} \\ x_{i2} \\ \vdots \\ x_{ip} \end{pmatrix}\]
Nun stecken wir die Parameter des Modells ebenfalls in einen Spaltenvektor:
\[\mathbf{w}=\begin{pmatrix} w_0 \\ w_1 \\ w_2 \\ \vdots \\ w_p \end{pmatrix}\]
Wie bereits für das Perceptron gesehen, können wir das lineare Regressionsmodell (für die Beobachtung \(i\)) als Skalarprodukt dieser beiden Vektoren aufschreiben:
\[\begin{align} f(\mathbf{x}_i) &= \mathbf{w}' \mathbf{x_i}\\ &= \begin{pmatrix} w_0 & w_1 & w_2 & \dots & w_p \end{pmatrix} \begin{pmatrix} 1\\ x_{i1} \\ x_{i2} \\ \vdots \\ x_{ip} \end{pmatrix}\\ &= w_0 \cdot 1 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \dots + w_p \cdot x_{ip} \end{align}\]
Frage
Doch Moment mal, das lineare Regressionsmodell sieht ja genau gleich wie ein Perceptron aus. Wie unterscheiden sich die beiden Modelle im Hinblick darauf, was mit \(\mathbf{w}' \mathbf{x_i}\) gemacht wird?
TippLösung
Grundsätzlich gilt: das Perceptron ist ein Klassifikationsmodell, während das lineare Regressionsmodell zur Lösung von Regressionsproblemen dient.
Beim Perceptron haben wir \(\mathbf{w}' \mathbf{x_i}\) verglichen mit dem Schwellenwert 0, um zu entscheiden, ob wir eine Beobachtung der Kategorie -1 oder +1 zuweisen.
Hier, beim linearen Regressionsmodell, soll \(\mathbf{w}' \mathbf{x_i}\) den stetigen (numerischen) Outputwert \(y_i\) möglichst gut abbilden.
Die Form \(\mathbf{w}' \mathbf{x_i}\) ist schon ziemlich kompakt, aber es geht noch besser. Wir können nämlich das Modell gleich für alle \(n\) Beobachtungen (und nicht nur für die \(i\)-te Beobachtung) aufschreiben. Dazu müssen wir die Input-Variablen für jede Beobachtung \(i\) in einer Matrix anordnen:
\[ \mathbf{X} = \begin{pmatrix} 1 & x_{11} & x_{12} & \cdots & x_{1p}\\ 1 & x_{21} & x_{22} & \cdots & x_{2p}\\ \vdots & \cdots & \cdots & \ddots & \vdots\\ 1 & x_{n1} & x_{n2} & \cdots & x_{np}\\ \end{pmatrix} \]
Die Matrix \(\mathbf{X}\) wird typischerweise Design Matrix genannt. Die erste Zeile enthält die Input-Variablen für die erste Beobachtung, die zweite Zeile die Input-Variablen für die zweite Beobachtung, usw. Nun können wir das Modell mithilfe einer Multiplikation zwischen der Design Matrix \(\mathbf{X}\) und dem Spaltenvektor \(\mathbf{w}\) in einem Schritt für alle Beobachtungen aufschreiben:
\[\begin{align} f(\mathbf{X}) &= \mathbf{X}\mathbf{w}\\ &= \begin{pmatrix} 1 & x_{11} & x_{12} & \cdots & x_{1p}\\ 1 & x_{21} & x_{22} & \cdots & x_{2p}\\ \vdots & \cdots & \cdots & \ddots & \vdots\\ 1 & x_{n1} & x_{n2} & \cdots & x_{np}\\ \end{pmatrix}\begin{pmatrix} w_0 \\ w_1 \\ w_2 \\ \dots \\ w_p \end{pmatrix}\\ &= \begin{pmatrix} w_0 \cdot 1 + w_1 \cdot x_{11} + w_2 \cdot x_{12} + \dots + w_p \cdot x_{1p} \\ w_0 \cdot 1 + w_1 \cdot x_{21} + w_2 \cdot x_{22} + \dots + w_p \cdot x_{2p} \\ \cdots \\ w_0 \cdot 1 + w_1 \cdot x_{n1} + w_2 \cdot x_{n2} + \dots + w_p \cdot x_{np}\end{pmatrix} \end{align}\]
Überprüfen wir doch noch kurz die Dimensionen von obigem Matrix-Vektor Produkt. Die Matrix \(\mathbf{X}\) hat \(n\) Zeilen und \(p+1\) Spalten und darum eine Dimensionalität von \(n \times (p+1)\). Der Spaltenvektor \(\mathbf{w}\) hat Dimensionalität \((p+1) \times 1\). Das Matrix-Vektor Produkt hat dementsprechend eine Dimensionalität von \(n \times 1\), genau was wir erwarten würden, nämlich einen (Spalten-)Vektor mit den Vorhersagen für alle \(n\) Beobachtungen.
VorsichtMatrixprodukt
Wenn das Produkt zweier Matrizen \(\mathbf{A}\) und \(\mathbf{B}\) gerechnet werden soll, dann gilt es immer zuerst die Dimensionen der beiden Matrizen zu prüfen. Warum? Die Multiplikation \(\mathbf{A}\mathbf{B}\) funktioniert nämlich nur dann, wenn die Anzahl Spalten von \(\mathbf{A}\) gleich der Anzahl Zeilen von \(\mathbf{B}\) ist.
Nehmen wir an, dass \(\mathbf{A}\) eine Dimensionalität von \(m \times n\) hat (\(\mathbf{A}\) hat also \(m\) Zeilen und \(n\) Spalten). Die Matrix \(\mathbf{B}\) hat eine Dimensionalität von \(n \times p\).
In diesem Fall ist obige Bedingung schon mal erfüllt, denn die Anzahl Spalten von \(\mathbf{A}\) (also \(n\)) ist gleich der Anzahl Zeilen von \(\mathbf{B}\).
Weiter gilt, dass die resultierenden Matrix \(\mathbf{C}=\mathbf{A}\mathbf{B}\) eine Dimensionalität von \(m \times p\) hat.
Doch wie berechnet man die Element der resultierenden Matrix \(\mathbf{C}\)?
Das erste Element links oben in der Matrix (man kann es als \(\mathbf{C}_{1,1}\) beschreiben) ist die Summe über die elementweisen Multiplikationen der Element in der ersten Zeile von \(\mathbf{A}\) und der ersten Spalte von \(\mathbf{B}\).
Oder allgemeiner: \(\mathbf{C}_{i,j} = \sum_{k=1}^n \mathbf{A}_{i,k} \cdot \mathbf{B}_{k,j}\).
Am einfachsten lässt sich das ganze an einem Beispiel anschauen:
\[\begin{align} \begin{pmatrix} 2 & -3 \\ 1 & 2 \end{pmatrix} \begin{pmatrix} 1.3 & -3 & 0 \\ 1 & 0.5 & 1 \end{pmatrix} &= \begin{pmatrix} 2\cdot 1.3 + (-3)\cdot 1 & 2\cdot (-3) + (-3)\cdot 0.5 & 2\cdot 0 + (-3)\cdot 1 \\ 1\cdot 1.3 + 2\cdot 1 & 1\cdot (-3) + 2\cdot 0.5 & 1\cdot 0 + 2\cdot 1 \end{pmatrix}\\ &= \begin{pmatrix} -0.4 & -7.5 & -3 \\ 3.3 & -2 & 2 \end{pmatrix}. \end{align}\]
Für unser einfaches Beispiel kann das Modell wie folgt in Matrixform geschrieben werden:
\[\begin{align} f(\mathbf{X}) &= \mathbf{X}\mathbf{w}\\ &= \begin{pmatrix} 1 & -4.1 \\ 1 & -0.5 \\ 1 & 1.4 \\ 1 & 4.4 \\ \end{pmatrix}\begin{pmatrix} w_0 \\ w_1 \end{pmatrix}\\ &= \begin{pmatrix} w_0 \cdot 1 - w_1 \cdot 4.1 \\ w_0 \cdot 1 - w_1 \cdot 0.5 \\ w_0 \cdot 1 + w_1 \cdot 1.4 \\ w_0 \cdot 1 + w_1 \cdot 4.4 \end{pmatrix} \end{align}\]
Warum wir all das tun, werden wir weiter unten sehen. Es wird unser Leben viel einfacher machen! Versuchen Sie diesen Abschnitt hier gut zu verstehen, so dass Sie sobald wie möglich mit der Matrixschreibweise von Modellen vertraut sind.
2.4 Modelltraining
Wir werden uns hier anschauen, wie für das Training (oft auch Fitting genannt) des linearen Regressionsmodells zwei verschiedene Perspektiven eingenommen werden können, welche am Schluss beide zum selben Resultat führen.
2.4.1 Perspektive 1: Funktionsoptimierung
In der ersten Perspektive behandeln wir das Modelltraining als Optimierungsproblem. Wir wollen nämlich eine sogenannte Kostenfunktion (engl. Loss Function) aufstellen, die es danach zu minimieren gilt. Sie werden gleich sehen, dass die Kostenfunktion für das lineare Regressionsmodell von den Modellparameter \(w_0,w_1,\dots,w_p\) abhängt. Das Ziel wird also sein, die optimalen Werte für die Modellparameter zu finden, so dass die Kostenfunktion so klein wie möglich ist.
Doch wie sieht denn nun diese Kostenfunktion für das lineare Regressionsmodell konkret aus? Wir werden uns hier der Einfachheit halber nur ein einfaches lineares Regressionsmodell mit nur einer Input-Variable \(x_i\) anschauen (wie in unserem einfachen Beispiel). Die Kostenfunktion sieht in diesem Fall so aus:
\[ J(\hat{w}_0,\hat{w}_1) = \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{f}(x_i) \right)^2 \]
Sie sehen, dass die Kostenfunktion \(J(\hat{w}_0,\hat{w}_1)\) eine Funktion der beiden (trainierten) Modellparameter ist. Vielleicht wundern Sie sich nun, wie diese Kostenfunktion von den Modellparameter abhängt, da diese in obiger Formel ja gar nicht direkt ersichtlich sind. Schreiben wir die Kostenfunktion doch mal etwas um:
\[\begin{align} J(\hat{w}_0, \hat{w}_1) &= \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{f}(x_i) \right)^2 \\ &= \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - (\hat{w}_0 + \hat{w}_1 \cdot x_i) \right)^2 \\ &= \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{w}_0 - \hat{w}_1 \cdot x_i \right)^2 \\ \end{align}\]
Nun ist offensichtlich, wie die Kostenfunktion \(J\) von den Modellparameter \(\hat{w}_0\) und \(\hat{w}_1\) abhängt. Im ML gibt es nun viele verschiedene Arten, wie man für die beiden Modellparameter die optimalen Werte findet. Hier ist die Lösung zum Glück einfach, denn es gibt eine sogenannte analytische Lösung, d.h. es ist möglich für \(\hat{w}_0\) und \(\hat{w}_1\) je eine Formel zu finden, die uns erlaubt die optimalen Parameterwerte direkt auszurechnen. Die Herleitung dieser Formeln ist nicht besonders schwierig, denn wir wenden nämlich ein altbekanntes Prinzip aus der Differenzialrechnung an: wir berechnen die erste Ableitung der Funktion nach den Modellparameter, setzen sie gleich Null und lösen nach dem Parameter auf.
Im folgenden Matheteil sehen Sie, wie wir die Formeln für die Berechnung der optimalen Parameterwerte des einfachen linearen Regressionsmodells herleiten können. Diese Methode wird Kleinstquadratemethode (engl. Least Squares) genannt, weil die optimalen Parameter die Summe über die quadrierten Differenzen zwischen \(y_i\) und den Vorhersagen \(\hat{f}(x_i)\) minimieren.
VorsichtKleinstquadratemethode
Wir leiten zuerst die Formel für \(\hat{w}_0\) her:
\[\begin{align} \frac{\partial J(\hat{w}_0, \hat{w}_1)}{\partial \hat{w}_0} &= \frac{1}{2n} \sum_{i=1}^{n} 2 \cdot \left(y_i - \hat{w}_0 - \hat{w}_1 \cdot x_i \right) \cdot (-1) \\ &= -\frac{1}{n} \sum_{i=1}^{n} \left(y_i - \hat{w}_0 - \hat{w}_1 \cdot x_i \right) \\ &= -\frac{1}{n} \sum_{i=1}^{n} y_i + \frac{1}{n} \sum_{i=1}^{n} \hat{w}_0 + \frac{1}{n} \sum_{i=1}^{n} \hat{w}_1 \cdot x_i \\ &= -\bar{y} + \frac{1}{n} \cdot n \cdot \hat{w}_0 + \hat{w}_1 \cdot \bar{x} \\ &= -\bar{y} + \hat{w}_0 + \hat{w}_1 \cdot \bar{x} \end{align}\]
Nun setzten wir die Ableitung gleich Null und lösen nach \(\hat{w}_0\) auf:
\[\begin{align} -\bar{y} + \hat{w}_0 + \hat{w}_1 \cdot \bar{x} &= 0 \\ \hat{w}_0 &= \bar{y} - \hat{w}_1 \cdot \bar{x} \end{align}\]
Wir sehen, dass die Lösung für \(\hat{w}_0\) von den beiden Mittelwerten \(\bar{y}\) und \(\bar{x}\) sowie von \(\hat{w}_1\) abhängt. Suchen wir nun also in einem zweiten Schritt die Lösung für \(\hat{w}_1\):
\[\begin{align} \frac{\partial J(\hat{w}_0, \hat{w}_1)}{\partial \hat{w}_1} &= \frac{1}{2n} \sum_{i=1}^{n} 2 \cdot \left(y_i - \hat{w}_0 - \hat{w}_1 \cdot x_i \right) \cdot (-x_i) \\ &= -\frac{1}{n} \sum_{i=1}^{n} \left(y_i \cdot x_i - \hat{w}_0 \cdot x_i - \hat{w}_1 \cdot x_i^2 \right) \\ &= -\frac{1}{n} \sum_{i=1}^{n} y_i \cdot x_i + \hat{w}_0 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 \\ &= -\frac{1}{n} \sum_{i=1}^{n} y_i \cdot x_i + \hat{w}_0 \cdot \bar{x} + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 \\ \end{align}\]
Nun können wir wiederum die Ableitung gleich Null setzen und für \(\hat{w}_0\) setzen wir unsere Lösung von oben ein. Danach lösen wir nach \(\hat{w}_1\) auf:
\[\begin{align} -\frac{1}{n} \sum_{i=1}^{n} y_i \cdot x_i + \hat{w}_0 \cdot \bar{x} + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 &= 0 \\ (\bar{y} - \hat{w}_1 \cdot \bar{x}) \cdot \bar{x} + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 &= \frac{1}{n} \sum_{i=1}^{n} y_i \cdot x_i \\ \bar{y} \cdot \bar{x} - \hat{w}_1 \cdot \bar{x}^2 + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 &= \frac{1}{n} \sum_{i=1}^{n} y_i \cdot x_i \\ \hat{w}_1 \left(\frac{1}{n} \sum_{i=1}^{n} x_i^2 - \bar{x}^2 \right) &= \frac{1}{n} \sum_{i=1}^{n} y_i \cdot x_i - \bar{y} \cdot \bar{x} \\ \hat{w}_1 &= \frac{\frac{1}{n} \sum_{i=1}^{n} y_i \cdot x_i - \bar{y} \cdot \bar{x}}{\frac{1}{n} \sum_{i=1}^{n} x_i^2 - \bar{x}^2} \end{align}\]
Vielleicht erkennen Sie die Ausdrücke im Zähler und Nenner der Lösung für \(\hat{w}_1\): es sind dies die Kovarianz zwischen \(y_i\) und \(x_i\) im Zähler und die Varianz von \(x_i\) im Nenner. Man kan die Formel also auch wie folgt aufschreiben:
\[ \hat{w}_1 = \frac{\text{Cov}(x, y)}{\text{Var}(x)} \]
Frage
Rechnen Sie nun die optimalen Parameterwerte für unser einfaches lineares Regressionsmodell aus. Sie können die verschiedenen statistischen Grössen entweder mithilfe von R rechnen oder von Hand bzw. mit dem Taschenrechner.
TippLösung
Wir rechnen als erstes die Mittelwerte für die beiden Variablen:
\[ \bar{x} = \frac{-4.1 + (-0.5) + 1.4 + 4.4}{4} = 0.3 \]
\[ \bar{y} = \frac{3.50 + 1.95 + (-2.50) + (-2.05)}{4} = 0.225 \]
Danach rechnen wir die mittlere Summe über die Produkte der jeweiligen Variablenwerte (erster Teil des Zählers der Formel für \(\hat{w}_1\)):
\[ \frac{3.50 \cdot (-4.1) + 1.95 \cdot (-0.5) + (-2.50) \cdot 1.4 + (-2.05) \cdot 4.4}{4} = -6.96125 \]
Nun rechnen wir die mittlere Summe über die quadrierten \(x\)-Werte (erster Teil des Nenners der Formel für \(\hat{w}_1\)):
\[ \frac{(-4.1)^2 + (-0.5)^2 + 1.4^2 + 4.4^2}{4} = 9.595 \]
Nun können wir den optimalen Parameterwert für \(\hat{w}_1\) berechnen:
\[ \hat{w}_1 = \frac{-6.96125 - 0.225 \cdot 0.3}{9.595 - 0.3^2} = -0.7395 \]
Und nun haben wir auch gleich alle Zutaten, um den optimalen Parameterwert für \(\hat{w}_0\) zu berechnen:
\[ \hat{w}_0 = 0.225 - (-0.7395) \cdot 0.3 = 0.4469 \]
Unser trainiertes optimales Modell sieht also wie folgt aus:
\[ \hat{f}(x_i) = 0.4469 - 0.7395 \cdot x_i \]
Das in der obigen Aufgabe berechnete Modell ist in der folgenden Abbildung (links) grafisch als blaue Gerade dargestellt. Der Parameter \(\hat{w}_0\) ist der Ort, an dem die Gerade die y-Achse durchkreuzt, während der Parameter \(\hat{w}_1\) der Steigung der Geraden entspricht. Unser optimales Modell minimiert die Summe über die quadrierten Differenzen zwischen den tatsächlichen \(y_i\) Werten und den Vorhersagen gemäss unserem Modell \(\hat{f}(x_i)\) (die Differenzen sind als rot gestrichelte Linien eingetragen).
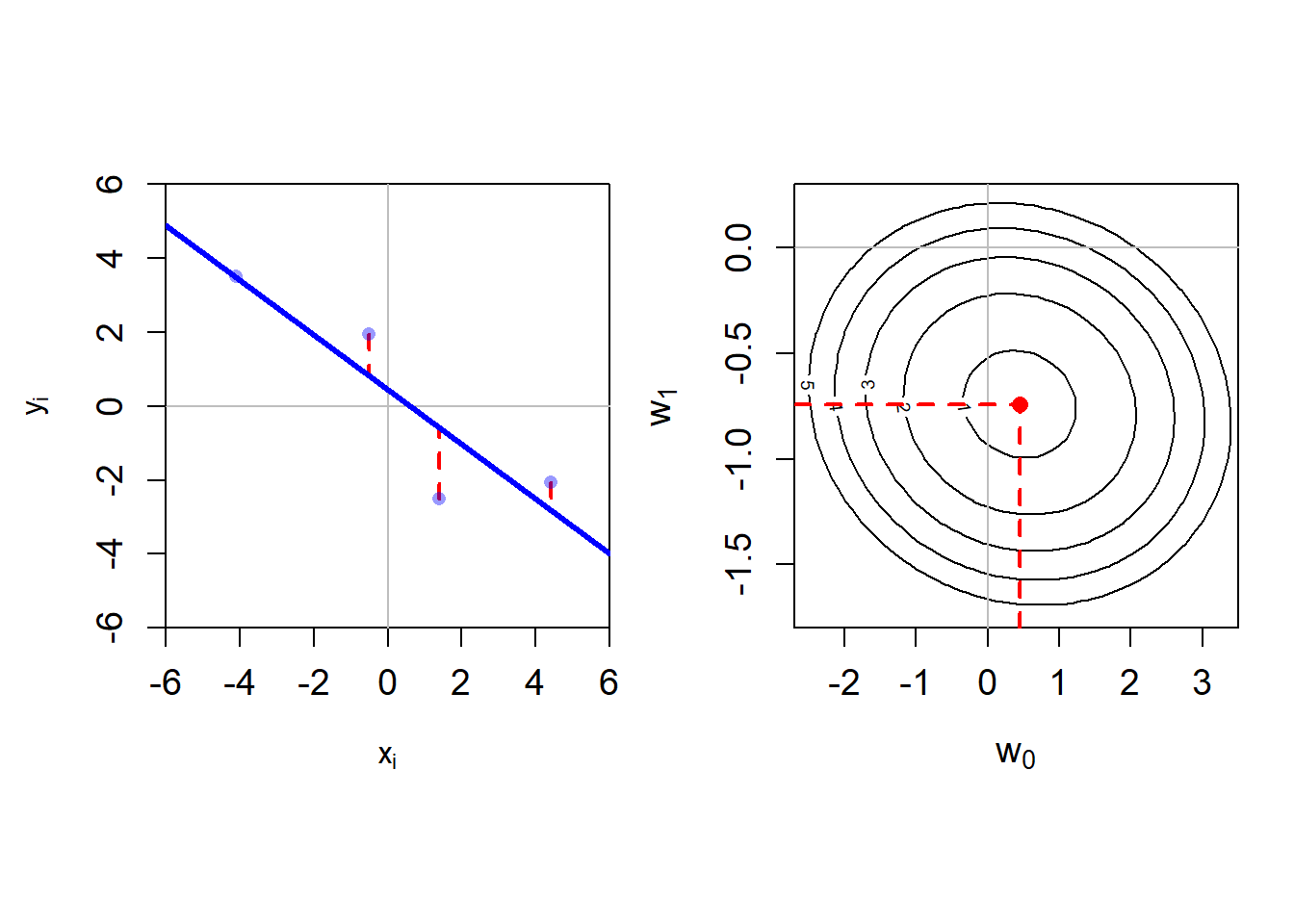
Die Abbildung (rechts) zeigt sogennante Konturlinien unserer Kostenfunktion. Die optimale Parameterwert-Kombination ist als roter Punkt eingezeichnet. Jede Konturlinie zeigt alle Parameterwert-Kombination, welche jeweils zum gleichen Kostenwert führen. Die fünf eingezeichneten Linien zeigen beispielsweise die Parameterwert-Kombination für die Kostenwerte 1 bis 5 (von innen nach aussen). Man kann sich unsere Kostenfunktion also wie eine Schüssel vorstellen mit dem roten Punkt als Boden der Schüssel. Es handelt sich bei unserer Kostenfunktion um eine Funktion, die quadratisch in den Parameterwerten \(\hat{w}_0\) und \(\hat{w}_1\) ist. In diesem Fall finden wir immer genau eine Parameterwert-Kombination, welche dem absoluten Minimum der Kostenfunktion entspricht. Manchmal spricht man auch von einer konvexen Kostenfunktion.
VorsichtKleinstquadratemethode in Matrixform (optional)
Die obige Herleitung funktioniert nur für das einfache lineare Regressionsmodell mit einer Input-Variable \(x_i\). Wir schauen uns hier nun kurz die allgemeine Lösung in Matrixform an. Wir nehmen an, dass die Werte unseres Outputs alle in einem Spaltenvektor \(\mathbf{y}\) organisiert sind und unsere Modellvorhersagen als \(\mathbf{X}\mathbf{\hat{w}}\) geschrieben werden können.
Dann können wir unsere Kostenfunktion von oben wie folgt in Matrixform schreiben:
\[\begin{align} J(\mathbf{\hat{w}}) &= \frac{1}{2n} (\mathbf{y} - \mathbf{X}\mathbf{\hat{w}})' (\mathbf{y} - \mathbf{X}\mathbf{\hat{w}}) \end{align}\]
Das sieht schlimmer aus als es ist, denn \((\mathbf{y} - \mathbf{X}\mathbf{\hat{w}})\) ist lediglich ein Spaltenvektor mit den Differenzen zwischen den wahren \(y_i\) und den Vorhersagen unseres Modells. Wenn wir diesen Spaltenvektor \(\mathbf{e}\) nennen, dann kann obiger Ausdruck als \(\frac{1}{2n} \mathbf{e}'\mathbf{e}\) geschrieben werden, wobei \(\mathbf{e}'\mathbf{e}\) ein Skalarprodukt ist und dementsprechend einen Skalar bzw. eine einzige Zahl zurück gibt. Diese Zahl multipliziert mit \(\frac{1}{2n}\) ist dann nichts anderes als der Wert unserer Kostenfunktion. Sie sehen also, dass wir mit dem Skalarprodukt \(\mathbf{e}'\mathbf{e}\) die Summe ersetzen können.
Nun wenden wir die bekannten Matrix-Rechenregeln an, um die Kostenfunktion umzuschreiben:
\[\begin{align} J(\mathbf{\hat{w}}) &= \frac{1}{2n} (\mathbf{y} - \mathbf{X}\mathbf{\hat{w}})' (\mathbf{y} - \mathbf{X}\mathbf{\hat{w}}) \\ &= \frac{1}{2n} (\mathbf{y}' - \mathbf{\hat{w}}' \mathbf{X}') (\mathbf{y} - \mathbf{X}\mathbf{\hat{w}}) \\ &= \frac{1}{2n} (\mathbf{y}'\mathbf{y} - \mathbf{y}'\mathbf{X}\mathbf{\hat{w}} - \mathbf{\hat{w}}' \mathbf{X}'\mathbf{y} + \mathbf{\hat{w}}' \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) \end{align}\]
Wenn Sie sich kurz anhand der Dimensionalität der einzelnen Komponenten überlegen, was das Endprodukt des Ausdrucks \(\mathbf{y}'\mathbf{X}\mathbf{\hat{w}}\) ist, dann werden Sie sehen, dass ein Skalar (Dimensionalität \(1 \times 1\)) resultiert. Darum muss zwingend auch die transponierte Form davon, \((\mathbf{y}'\mathbf{X}\mathbf{\hat{w}})'=\mathbf{\hat{w}}' \mathbf{X}'\mathbf{y}\) ein Skalar sein, was dazu führt, dass die beiden mittleren Terme in der letzten Zeile von obiger Kostenfunktion identisch sein müssen. Deshalb können wir die Kostenfunktion wie folgt umschreiben:
\[\begin{align} J(\mathbf{\hat{w}}) &= \frac{1}{2n} (\mathbf{y}'\mathbf{y} - 2\mathbf{y}'\mathbf{X}\mathbf{\hat{w}} + \mathbf{\hat{w}}' \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) \end{align}\]
So, nun können wir die Kostenfunktion nach dem Spaltenvektor mit den Modellparameter \(\mathbf{\hat{w}}\) ableiten. Man spricht in diesem Fall nun nicht von einer Ableitung, sondern von einem Gradienten. Auch die mathematische Schreibweise ist etwas anders:
\[\begin{align} \nabla_{\mathbf{\hat{w}}} J(\mathbf{\hat{w}}) &= \frac{1}{2n} (- 2\mathbf{X}'\mathbf{y} + 2\mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) \\ &= \frac{1}{n} (-\mathbf{X}'\mathbf{y} + \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) \end{align}\]
Diesen Ausdruck können wir nun wie gewohnt gleich Null setzen (wobei wir hier rechts einen Nullvektor \(\mathbf{0}\) setzen) und mit den Matrix-Rechenregeln nach \(\mathbf{\hat{w}}\) auflösen:
\[\begin{align} \frac{1}{n} (-\mathbf{X}'\mathbf{y} + \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) &= \mathbf{0} \\ \mathbf{X}'\mathbf{X}\mathbf{\hat{w}} &= \mathbf{X}'\mathbf{y} \\ \mathbf{\hat{w}} &= (\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y} \end{align}\]
Wichtig: Die Matrix \(\mathbf{X}'\mathbf{X}\) hat eine Dimensionalität von \((p+1) \times (p+1)\), ist also quadratisch. Sie ist nur invertierbar, wenn die Design Matrix mehr Zeilen als Spalten hat, also wenn \(n > (p+1)\).
Gütemasse für die Regression
Eine Form der hier verwendeten Kostenfunktion wird oft auch als Gütemass für die Vorhersagen eines Regressionsmodells verwendet. In diesem Zusammenhang sprechen wir dann vom Mean Squared Error (MSE). Mit diesen Gütemassen beurteilen wir die Vorhersagegüte von fertig trainierten Modellen; sie haben also nichts mit dem Training zu tun.
Häufig wird nicht der MSE sondern der Root Mean Squared Error (RMSE) verwendet, so dass das resultierende Fehlermass auf derselben Skala wie die Vorhersagen “lebt”. Oder anders gesagt, wir neutralisieren den Effekt des Quadrierens wieder. Die Formel für den RMSE sieht wie folgt aus:
\[ RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} \left(y_i - \hat{f}(x_i) \right)^2} \]
Eine Alternative zum RMSE ist der Mean Absolute Error (MAE), der wie folgt definiert ist:
\[ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{f}(x_i)| \] Der MAE hat im Vergleich zum RMSE den Vorteil, dass er wengier stark auf grosse Differenzen zwischen dem wahren und vorhergesagten Wert für \(y\) reagiert, oder, in anderen Worten, robuster gegen Ausreisser ist.3
2.4.2 Perspektive 2: Wahrscheinlichkeitstheorie
Nun werden wir sehen, dass wir die Lösung oben (aus Perspektive 1) auch mit einer probabilistischen Sicht auf die Dinge erhalten. Dazu schreiben wir nochmals kurz den allgemein angenommenen Zusammenhang zwischen dem wahren Output \(y_i\) und den Input-Variablen auf und konkretisieren ihn dann gleich für das lineare Regressionsmodell:
\[\begin{align} y_i &= f(\mathbf{x}_i) + \epsilon \\ &= \mathbf{w}' \mathbf{x_i} + \epsilon \\ \end{align}\]
Nun nehmen wir an, dass der Fehlerterm \(\epsilon\) normalverteilt ist mit Mittelwert 0 und Varianz \(\sigma^2\), also \(\epsilon \sim N(0,\sigma^2)\). Weil wir annehmen, dass \(\mathbf{w}' \mathbf{x_i}\) fix ist (also keine Zufallsvariable), ist unser Output \(y_i\) normalverteilt mit Mittelwert \(\mathbf{w}' \mathbf{x_i}\) und Varianz \(\sigma^2\):
\[ y_i \sim \mathcal{N}\left(\mathbf{w}' \mathbf{x_i}, \sigma^2\right) \]
Folgende Abbildung illlustriert diese Annahme: an jedem Ort \(x_i\) ist der entsprechende Outputwert \(y_i\) eine Realisierung (oder Ziehung) aus einer Normalverteilung mit Mittelwert \(\mathbf{w}' \mathbf{x_i}\) und Varianz \(\sigma^2\).
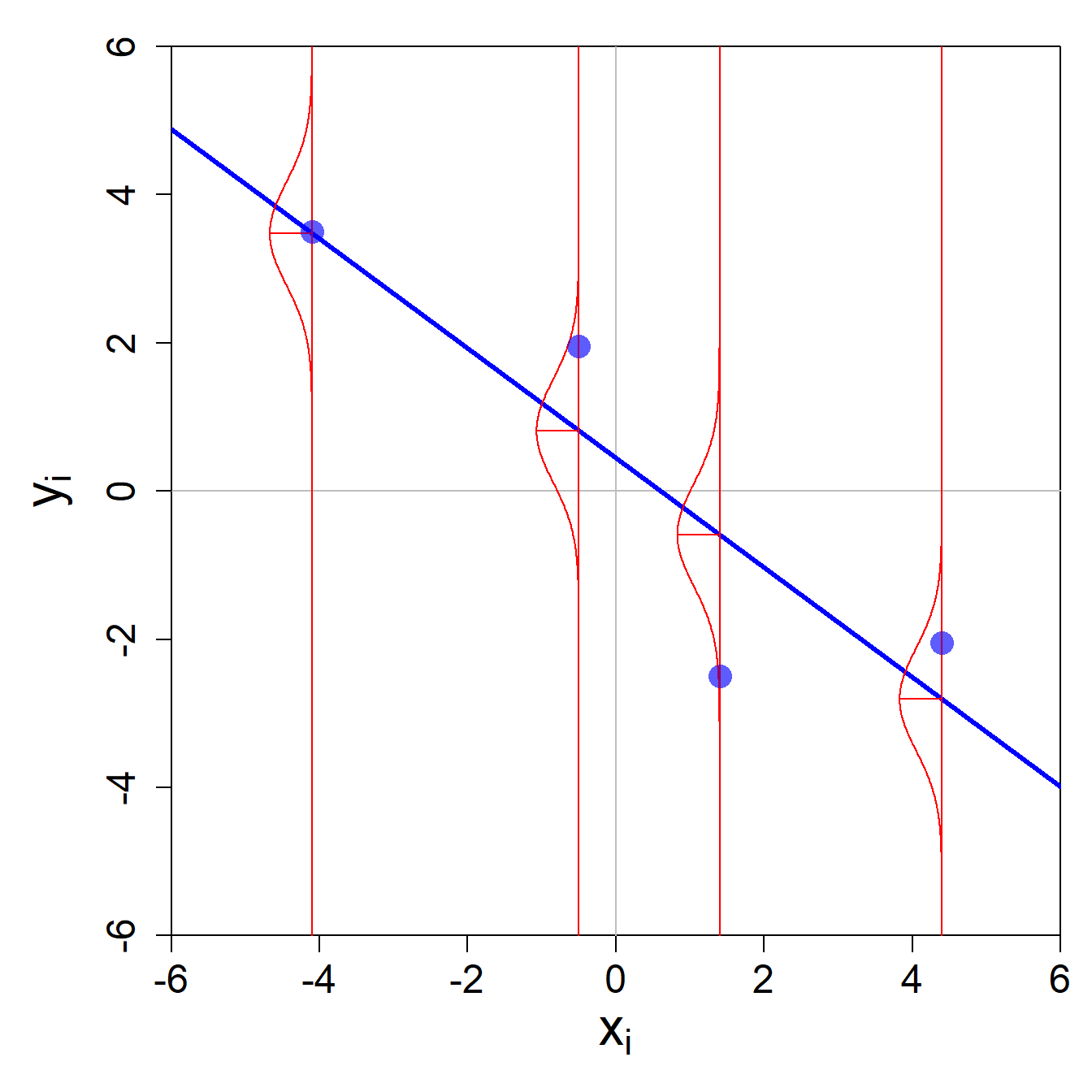
Nun möchten wir wissen, was die gemeinsame Verteilung aller Output-Werte in unserem Datensatz ist. D.h. wie sieht die Wahrscheinlichkeit \(p(y_1,y_2,\dots,y_n|\mathbf{w},\mathbf{X},\sigma^2)\) aus? Weil wir annehmen, dass alle Beobachtungen \(i\) in unserem Datensatz unabhängig sind und die Wahrscheinlichkeiten der einzelnen Beobachtungen \(i\) darum multipliziert werden können, sieht die Antwort auf die Frage folgendermassen aus:
\[ p(y_1,y_2,\dots,y_n\mid\mathbf{w},\mathbf{X},\sigma^2) = \prod_{i=1}^n \mathcal{N}\left(\mathbf{w}' \mathbf{x_i}, \sigma^2\right) \]
HinweisMaximum Likelihood
Die gemeinsame Wahrscheinlichkeit \(p(y_1,y_2,\dots,y_n\mid\mathbf{w},\mathbf{X},\sigma^2)\) der beobachteten Output-Werte, gegeben die Input-Werte und das Modell (charakterisiert durch dessen Parameter \(\mathbf{w}\) und \(\sigma^2\)), wird in der Fachsprache Likelihood genannt.
Die zentrale Idee hier ist, dass wir die Modellparameter \(\mathbf{w}\) so wählen, dass die Likelihood maximal wird. Der daraus folgende Ausdruck für \(\mathbf{w}\) wird Maximum Likelihood Schätzer genannt und oft als ML abgekürzt, was sehr verwirrlich sein kann, da wir ja auch Machine Learning so abkürzen.
Mit dem ML-Schätzer finden wir also dasjenige (lineare) Modell (bzw. dessen Parameterwerte), das die beobachteten \(y_i\)-Werte maximal wahrscheinlich macht.
VorsichtMaximum Likelihood Herleitung (optional)
Wir können nun in der Likelihood oben anstelle von \(\mathcal{N}\left(\mathbf{w}' \mathbf{x_i}, \sigma^2\right)\) jeweils die Dichtefunktion der Normalverteilung einsetzen:
\[\begin{align} p(y_1,y_2,\dots,y_n|\mathbf{w},\mathbf{X},\sigma^2) &= \prod_{i=1}^n \mathcal{N}\left(\mathbf{w}' \mathbf{x_i}, \sigma^2\right) \\ &= \prod_{i=1}^n \frac{1}{\sigma\sqrt{2\pi}} \exp\left( -\frac{1}{2}\left(\frac{y_i - \mathbf{w}' \mathbf{x_i}}{\sigma}\right)^{\!2}\,\right) \end{align}\]
Nun vollziehen wir einen kleinen mathematischen Trick, der vielfach angewendet wird: anstelle der Likelihood verwenden wir nun den natürlichen Logarithmus der Likelihood (Log-Likelihood). Das ist möglich, weil sich so das Optimierungsproblem nicht verändert. Das Logarithmieren vereinfacht das Problem ungemein, denn der Logarithmus eines Produkts wird zu einer Summe der logarithmierten Elemente:
\[\begin{align} \text{ln}\; p(y_1,y_2,\dots,y_n|\mathbf{w},\mathbf{X},\sigma^2) &= \text{ln}\left(\prod_{i=1}^n \frac{1}{\sigma\sqrt{2\pi}} \exp\left( -\frac{1}{2}\left(\frac{y_i - \mathbf{w}' \mathbf{x_i}}{\sigma}\right)^{\!2}\,\right)\right) \\ &= \sum_{i=1}^n \text{ln}\left(\frac{1}{\sigma\sqrt{2\pi}} \exp\left( -\frac{1}{2}\left(\frac{y_i - \mathbf{w}' \mathbf{x_i}}{\sigma}\right)^{\!2}\,\right) \right) \\ &= \sum_{i=1}^n \text{ln}\left(1\right) - \text{ln}\left(\sigma\sqrt{2\pi}\right) - \frac{1}{2}\left(\frac{y_i - \mathbf{w}' \mathbf{x_i}}{\sigma}\right)^{\!2} \\ &= \sum_{i=1}^n \text{ln}\left(1\right) - \sum_{i=1}^n \text{ln}\left(\sigma\sqrt{2\pi}\right) - \sum_{i=1}^n \frac{1}{2}\left(\frac{y_i - \mathbf{w}' \mathbf{x_i}}{\sigma}\right)^{\!2} \\ &= n \cdot \text{ln}\left(1\right) - n \cdot \text{ln}\left(\sigma\sqrt{2\pi}\right) - \frac{1}{2\sigma^2} \sum_{i=1}^n \left(y_i - \mathbf{w}' \mathbf{x_i}\right)^{\!2} \end{align}\]
Wow, nun haben wir ein tolles Resultat gefunden: je kleiner der Term \(\sum_{i=1}^n \left(y_i - \mathbf{w}' \mathbf{x_i}\right)^{\!2}\) in obiger Gleichung, desto grösser ist der natürliche Logarithmus der Likelihood. Das heisst nichts anderes, als dass die Kleinstquadratemethode auch der Maximum Likelihood Schätzer ist.
Wir haben mit der Annahme begonnen, dass unser Output \(y_i\) normalverteilt ist, d.h. \(y_i \sim \mathcal{N}\left(\mathbf{w}' \mathbf{x_i}, \sigma^2\right)\). Wir haben nun herausgefunden, dass der mit der Kleinstquadratemethode berechnete Vektor \(\mathbf{w}\) auch glech dem ML-Schätzer entspricht. Um die Normalverteilung vollkommen zu spezifizieren, benötigen wir nun noch eine Formel, um die Varianz \(\sigma^2\) zu rechnen. Dazu leiten wir den obigen Ausdruck der Log-Likelihood nach \(\sigma\) ab:
\[\begin{align} \frac{\partial \text{ln}\; p(y_1,y_2,\dots,y_n|\mathbf{w},\mathbf{X},\sigma^2)}{\partial \sigma} &= -n\cdot \frac{\sqrt{2\pi}}{\sigma\sqrt{2\pi}} - (-\frac{2}{\sigma^3}) \cdot \frac{1}{2} \sum_{i=1}^n \left(y_i - \mathbf{w}' \mathbf{x_i}\right)^{\!2} \\ &= -\frac{n}{\sigma} + \frac{1}{\sigma^3} \sum_{i=1}^n \left(y_i - \mathbf{w}' \mathbf{x_i}\right)^{\!2} \end{align}\]
Nun können wir wie gewohnt die Ableitung gleich Null setzen und nach \(\sigma\) auflösen:
\[\begin{align} -\frac{n}{\hat{\sigma}} + \frac{1}{\hat{\sigma}^3} \sum_{i=1}^n \left(y_i - \mathbf{\hat{w}}' \mathbf{x_i}\right)^{\!2} &= 0 \\ \frac{n}{\hat{\sigma}} &= \frac{1}{\hat{\sigma}^3} \sum_{i=1}^n \left(y_i - \mathbf{\hat{w}}' \mathbf{x_i}\right)^{\!2} \\ \frac{\hat{\sigma}^3}{\hat{\sigma}} &= \frac{1}{n} \sum_{i=1}^n \left(y_i - \mathbf{\hat{w}}' \mathbf{x_i}\right)^{\!2} \\ \hat{\sigma}^2 &= \frac{1}{n} \sum_{i=1}^n \left(y_i - \mathbf{\hat{w}}' \mathbf{x_i}\right)^{\!2} \\ \end{align}\]
Sehr schön, dieses Resultat macht ebenfalls viel Sinn. Die geschätzte Varianz \(\hat{\sigma}^2\) ist nichts anderes als der durchschnittliche quadrierte Fehler (engl. Mean Squared Error).
2.5 Regularisierte Regression
Das zentrale Problem der oben kennen gelernten Kleinstquadratemethode ist, dass sie extrem anfällig auf Overfitting ist. Vereinfacht gesagt bedeutet Overfitting, dass sich das Modell zu fest an die Trainingsdaten anpasst und die aus den Daten gelernten Muster nicht mehr generalisierbar sind.
Beim linearen Regressionsmodell ist Overfitting vor allem dann ein Problem, wenn die Anzahl Input-Variablen \(p\) relativ gross ist im Vergleich zur Anzahl Beobachtungen \(n\). Im Extremfall haben wir mehr Input-Variablen als Beobachtungen (\((p+1)>n\)), was dazu führt, dass der Kleinstquadrateschätzer mathematisch nicht rechenbar ist.4 Das sollte auch intuitiv Sinn machen, denn wie soll eine Schätzung funktionieren, wenn wir im Schnitt weniger als eine Beobachtung pro zu schätzenden Parameter haben.
Wir können das Problem des Overfittings weitgehend lösen, indem wir ein regularisiertes Regressionsmodell rechnen. Regularisierung bedeutet eigentlich nichts anderes, als dass wir die ursprüngliche Kostenfunktion für das lineare Regressionsmodell modifizieren. Dabei gibt es zwei bekannte Regularisierungsarten, nämlich Ridge oder LASSO. Wir fokussieren in einem ersten Schritt auf die Ridge Regularisierung, weil wir in diesem Fall wiederum eine analytische Lösung finden.
2.5.1 Ridge Regressionsmodell
Die Kostenfunktion für das Ridge Regressionsmodell sieht wie folgt aus:
\[ J(\mathbf{w}) = \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{f}(\mathbf{x}_i) \right)^2 + \frac{\lambda}{2} \cdot \sum_{j=1}^p w_j^2 \]
Diese modifizierte Kostenfunktion hat etwas Erklärungsbedarf:
- Wir versuchen hier Modellparameter \(\mathbf{w}\) zu finden, welche gleichzeitig den durchschnittlichen quadrierten Fehler sowie eine Summe über die quadrierten Modellparameter so klein wie möglich machen. Das sind zwei konkurrenzierende Ziele und während des Modelltrainings muss der beste Tradeoff gefunden werden.
- Der Regularisierungsterm ist eine Summe über die quadrierten Modellparameter. Das Quadrieren stellt sicher, dass sich positive und negative Parameterwerte nicht gegenseitig kompensieren.
- Der Hyperparameter \(\lambda\) legt fest, wie viel (relatives) Gewicht der Regularisierungsterm im Verhältnis zum durchschnittlichen quadrierten Fehler bekommt. Je grösser \(\lambda\), desto stärker “bestrafen” wir komplexe Modelle. Wir werden später sehen, wir wir den optimalen Wert für \(\lambda\) via Cross-Validation finden können.
- Der Regularisierungsterm enthält die Konstante \(w_0\) nicht (die Summe startet bei \(j=1\) und nicht bei \(j=0\)). Die Konstante des Modells wird also nie regularisiert, denn sie definiert lediglich den Punkt, wo die Gerade (oder die Hyperebene im Fall von mehr als einer Input-Variable) die y-Achse schneidet. Dieser Parameter soll flexibel bleiben.
Fragen
- Was passiert wenn \(\lambda=0\)?
- Was passiert wenn \(\lambda \rightarrow \infty\)?
TippLösung
- Wenn \(\lambda=0\), dann entfällt der Regularisierungsterm und wir haben die altbekannte Kostenfunktion. Die resultierenden Parameter entsprechen dem Kleinstquadrateschätzer.
- Wenn \(\lambda \rightarrow \infty\), dann wird der Regularisierungsterm so wichtig, dass alle Gewichte \(w_1,\dots, w_p\) auf 0 gesetzt werden. Es resultiert folgendes Modell: \(\hat{f}(\mathbf{x_i}) = \hat{w}_0\).
Berechnen Sie hier nun den optimalen Parameter \(\hat{w}_1\) für ein einfaches regularisiertes Regressionsmodell mit nur einer \(x_i\)-Variable.
- Leiten Sie dazu die obige Kostenfunktion nach \(\hat{w}_1\) ab, setzen Sie sie gleich Null und lösen Sie nach \(\hat{w}_1\) auf.
- Für \(\hat{w}_0\) können Sie die Lösung aus dem unregularisierten Fall einsetzen, also \(\hat{w}_0 = \bar{y} - \hat{w}_1 \cdot \bar{x}\).
TippLösung
Die Kostenfunktion für das einfache regularisierte Modell sieht konkret wie folgt aus:
\[ \begin{aligned} J(\hat{w}_0, \hat{w}_1) &= \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{w}_0 - \hat{w}_1 \cdot x_i \right)^2 + \frac{\lambda}{2} \hat{w}_1^2 \end{aligned} \]
Nun leiten wir diese Kostenfunktion nach \(\hat{w}_1\) ab und gehen durch sehr ähnliche Schritte wie im unregularisierten Fall:
\[ \begin{aligned} \frac{\partial J(\hat{w}_0, \hat{w}_1)}{\partial \hat{w}_1} &= \frac{1}{2n} \sum_{i=1}^{n} 2 \cdot \left(y_i - \hat{w}_0 - \hat{w}_1 \cdot x_i \right) \cdot (-x_i) + \frac{2\lambda}{2} \hat{w}_1 \\[6pt] &= -\frac{1}{n} \sum_{i=1}^{n} \left(y_i x_i - \hat{w}_0 x_i - \hat{w}_1 x_i^2 \right) + \lambda \hat{w}_1 \\[6pt] &= -\frac{1}{n} \sum_{i=1}^{n} y_i x_i + \hat{w}_0 \bar{x} + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 + \lambda \hat{w}_1 \\[6pt] &= -\frac{1}{n} \sum_{i=1}^{n} y_i x_i + (\bar{y} - \hat{w}_1 \bar{x}) \cdot \bar{x} + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 + \lambda \hat{w}_1 \\[6pt] &= -\frac{1}{n} \sum_{i=1}^{n} y_i x_i + \bar{y}\bar{x} - \hat{w}_1 \bar{x}^2 + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 + \lambda \hat{w}_1 \end{aligned} \]
Nun setzen wir die Ableitung gleich Null und lösen nach \(\hat{w}_1\) auf:
\[ \begin{aligned} -\frac{1}{n} \sum_{i=1}^{n} y_i x_i + \bar{y}\bar{x} - \hat{w}_1 \bar{x}^2 + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 + \lambda \hat{w}_1 &= 0 \\[6pt] -\hat{w}_1 \bar{x}^2 + \hat{w}_1 \cdot \frac{1}{n} \sum_{i=1}^{n} x_i^2 + \lambda \hat{w}_1 &= \frac{1}{n} \sum_{i=1}^{n} y_i x_i - \bar{y}\bar{x} \\[6pt] \hat{w}_1 \left( \frac{1}{n} \sum_{i=1}^{n} x_i^2 - \bar{x}^2 + \lambda \right) &= \frac{1}{n} \sum_{i=1}^{n} y_i x_i - \bar{y}\bar{x} \\[6pt] \hat{w}_1 &= \frac{\mathrm{Cov}(y,x)}{\mathrm{Var}(x) + \lambda} \end{aligned} \]
Ha, das macht ja irgendwie Sinn. Je größer der Wert für \(\lambda\), desto grösser der Nenner und desto stärker wird der trainierte Wert für \(\hat{w}_1\) beschränkt.
VorsichtRidge Regression in Matrixform (optional)
Der Einfachheit halber nehmen wir hier an, dass die Outputwerte \(y_i\) hier standardisiert5 wurden, so dass der Mittelwert über die standardisierten Outputwerte Null ist. So entfällt die Konstante \(w_0\) aus dem Modell, was uns die Matrixform für das Ridge Modell erleichtert, denn der Regularisierungsterm soll ja die Konstante nicht enthalten und wenn es diese nicht gibt, dann gibt es keine Probleme.
Wie weiter oben gesehen, können wir die Kostenfunktion für das nicht-regularisierte Modell wie folgt schreiben:
\[\begin{align} J(\mathbf{\hat{w}}) &= \frac{1}{2n} (\mathbf{y}'\mathbf{y} - 2\mathbf{y}'\mathbf{X}\mathbf{\hat{w}} + \mathbf{\hat{w}}' \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) \end{align}\]
Der Regularisierungsterm kann sehr einfach in Matrixform geschrieben werden, nämlich als Skalarprodukt \(\frac{\lambda}{2}\mathbf{\hat{w}}'\mathbf{\hat{w}}\). Damit kriegen wir folgende Kostenfunktion:
\[\begin{align} J(\mathbf{\hat{w}}) &= \frac{1}{2n} (\mathbf{y}'\mathbf{y} - 2\mathbf{y}'\mathbf{X}\mathbf{\hat{w}} + \mathbf{\hat{w}}' \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) + \frac{\lambda}{2}\mathbf{\hat{w}}'\mathbf{\hat{w}} \end{align}\]
Um den Gradienten dieser Kostenfunktion zu finden, gehen wir nun sehr ähnlich wie oben vor:
\[\begin{align} \nabla_{\mathbf{\hat{w}}} J(\mathbf{\hat{w}}) &= \frac{1}{2n} (- 2\mathbf{X}'\mathbf{y} + 2\mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) + \frac{2\lambda}{2}\mathbf{\hat{w}} \\ &= \frac{1}{n} (-\mathbf{X}'\mathbf{y} + \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) + \lambda \mathbf{\hat{w}} \end{align}\]
Diesen Ausdruck können wir nun wie gewohnt gleich Null setzen und mit den Matrix-Rechenregeln nach \(\mathbf{\hat{w}}\) auflösen:
\[\begin{align} \frac{1}{n} (-\mathbf{X}'\mathbf{y} + \mathbf{X}'\mathbf{X}\mathbf{\hat{w}}) + \lambda \mathbf{\hat{w}} &= \mathbf{0} \\ \mathbf{X}'\mathbf{X}\mathbf{\hat{w}} + \lambda \mathbf{\hat{w}} &= \mathbf{X}'\mathbf{y} \\ (\mathbf{X}'\mathbf{X} + \lambda \mathbf{I}) \mathbf{\hat{w}} &= \mathbf{X}'\mathbf{y} \\ \mathbf{\hat{w}} &= (\mathbf{X}'\mathbf{X} + \lambda \mathbf{I})^{-1}\mathbf{X}'\mathbf{y} \\ \end{align}\]
Wichtig: \((\mathbf{X}'\mathbf{X} + \lambda \mathbf{I})\) ist immer invertierbar, auch wenn \(p>n\). Wir haben nun also ein analytisch lösbares Regressionsmodell gefunden, dass gut gegen Overfitting schützt.
HinweisStandardisierung der Input-Variablen
Es ist eminent wichtig, dass Sie alle numerischen Input-Variablen vor der Anwendung eines regularisierten Modells standardisieren, so dass alle Variablen auf der selben Skala “leben”. Warum ist das so wichtig? Sie haben gesehen, dass wir beim Ridge Modell die Grösse der Parameter mit dem Regularisierungsterm beschränken. Wenn jedoch die Input-Variablen alle auf unterschiedlichen Skalen “leben”, dann sind die Parameter nur schon deshalb unterschiedlich. Durch die Standardisierung der Input-Variablen erreichen wir, dass die Parametergrössen vergleichbar werden und die Regularisierung so auch korrekt funktioniert.
2.5.2 LASSO Regressionsmodell
Beim LASSO6 Modell verwenden wir einen anderen Regularisierungsterm als bei Ridge. Anstatt die Parameter zu quadrieren (um Kompensationseffekte zu vermeiden), verwenden wir den absoluten Wert, d.h. wir ignorieren die Vorzeichen der Parameter:
\[ J(\mathbf{w}) = \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{f}(\mathbf{x}_i) \right)^2 + \lambda \cdot \sum_{j=1}^p |w_j| \]
Die Optimierung der LASSO Kostenfunktion hat allerdings einen gewichtigen Vorteil gegenüber Ridge, der nicht so offensichtlich ist: unwichtige Parameter werden bei LASSO auf 0 gesetzt, während Ridge die Parameter einfach kleiner macht, sie aber nie auf genau 0 setzt (ausser wenn \(\lambda \to \infty\)). Das Modell nimmt also selbständig eine Selektion der wichtigen Variablen vor. Diese Eigenschaft macht das Modell auch gut interpretierbar, weil bei korrekter Anwendung von LASSO nur die relevanten Input-Variablen im Modell verbleiben.
VorsichtWie funktioniert diese Variablenselektion bei LASSO? (optional)
Um besser zu verstehen, warum LASSO eine automatische Variablenselektion vornimmt und die Modellparameter unwichtiger Input-Variablen auf Null setzt, muss das Optimierungsproblem in die Lagrange-Form (eingeschränkte Optimierung) gebracht werden:
\[ \text{Minimiere}\quad \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{f}(\mathbf{x}_i) \right)^2 \text{unter der Bedingung}\quad \sum_{j=1}^p |w_j| \leq s \] \(s\) kann als Budget interpretiert werden (James u. a. 2021, pp. 241 - 245) und die Summe über die absoluten Werte der Modellparameter kann dieses Budget nicht übersteigen.
Jedes Budget \(s\) matcht einen Wert für \(\lambda\), so dass dieselben Modellparameter resultieren. Oder in anderen Worten: die Problemformulierung hier ist identisch zu der obigen mit dem Unterschied, dass sie hier durch \(s\) charakterisiert ist und oben durch \(\lambda\).
Die Bedingung \(\sum_{j=1}^p |w_j| \leq s\) kann im Fall von zwei Input-Variablen mit den entsprechenden Modellparameter \(w_1\) und \(w_2\) gut visualisert werden:
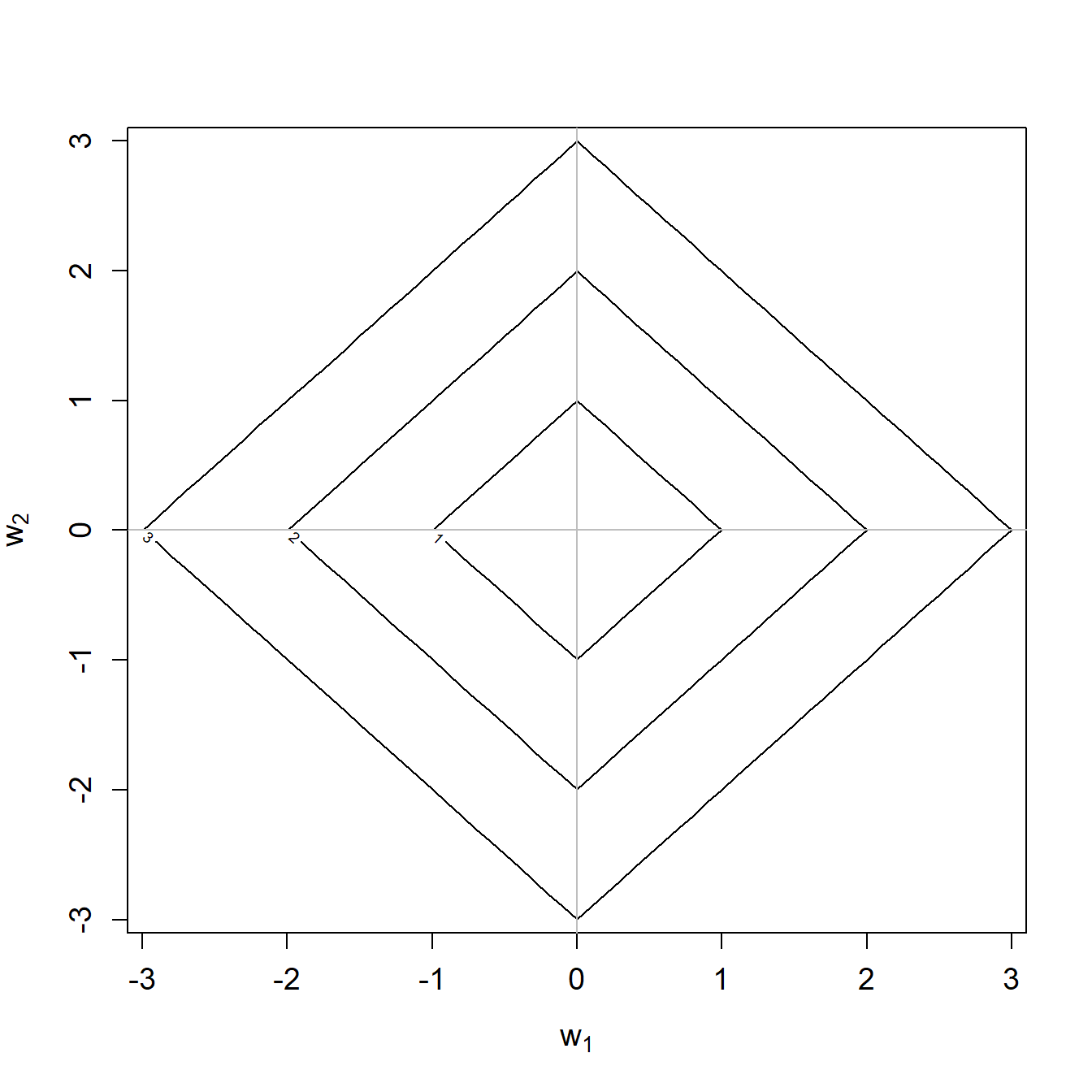
Die drei abgebildeten Rauten entsprechend den Budgets \(s=1,2,3\). Jede Raute enthalt alle Kombinationen von Parameterwerten, welche zusammen genau das Budget ergeben. Wenn wir uns beispielsweise den Eckpunkt ganz oben in der äussersten Raute anschauen, dann haben wir dort die Parameterwerte \(w_1=0\) und \(w_2=3\); die Summe der absoluten Werte ist also genau 3.
Die optimalen LASSO Modellparameter befinden sich nun an dem Punkt, wo die Konturlinien für den ersten Teil der Kostenfunktion (die Summe der quadrierten Differenzen, siehe auch Konturlinien oben für Kleinstquadratemethode) die Konturlinie der LASSO-Bedingung für ein gegebenes Budget \(s\) berühren. Ganz oft ist dieser Berührungspunkt in einer der Ecken. Wichtig: eine Ecke ist immer eine Parameterkombination, wo einer der Parameter den Wert 0 hat.
Der Nachteil von LASSO im Vergleich zu Ridge ist, dass es keine analytische Lösung gibt. In der praktischen Arbeit stört uns dies allerdings nur wenig, da R oder Python Packages gut gerüstet sind, um das Optimierungsproblem für LASSO zu lösen.
Wichtig: wie bei Ridge müssen auch hier alle numerischen Input-Variablen zwingend standardisiert sein.
2.6 Bias-Variance Tradeoff
Wir haben oben bereits gesehen, dass der Hyperparameter \(\lambda\) bestimmt, wie stark die Komplexität des Regressionsmodells eingeschränkt wird (oder in anderen Worten, die Parameter richtung Null geschrumpft werden).
Um noch besser zu verstehen, warum es so wichtig ist, die Komplexität eines Modells korrekt einzustellen, wollen wir uns nun mit einem ganz wichtigen Konzept im Machine Learning beschäftigen, nämlich dem Bias-Variance Tradeoff. Dieses Konzept kann intuitiv für alle Bereiche des Supervised Learnings angewendet werden. Für das Regressionsproblem können wir diesen Tradeoff jedoch auch mathematisch herleiten (siehe auch James u. a. 2021) und genau das tun wir jetzt hier.
Stellen Sie sich vor, dass wir eine grosse Anzahl Trainingsdatensätze zur Verfügung haben und mit jedem dieser Datensätze versuchen wir den wahren funktionalen Zusammenhang \(f(\mathbf{x}_i)\) möglichst gut mit \(\hat{f}(\mathbf{x}_i)\) zu schätzen. Für jeden Datensatz sieht das geschätzte Modell \(\hat{f}(\mathbf{x}_i)\) etwas anders aus (da es auf einem unterschiedlichen Datensatz trainiert wurde). Das geschätzte Modell, kurz \(\hat{f}\), variiert also je nach Datensatz und ist dementsprechend eine Zufallsvariable.
Ausserdem treffen wir folgende Annahmen:
- Von oben wissen wir, dass \(y_i = f(\mathbf{x}_i) + \epsilon\) immer gilt.
- Wir nehmen an, dass der Erwartungswert des nicht-lernbaren Teils \(\epsilon\) Null ist, also \(\mathbb{E}[\epsilon]=0\).
- Ausserdem gilt für die Varianz einer Zufallsvariable (in Kombination mit der zweiten Annahme, dass \(\mathbb{E}[\epsilon]=0\)): \(\text{Var}(\epsilon) = \mathbb{E}[\epsilon^2] - \mathbb{E}[\epsilon]^2 = \mathbb{E}[\epsilon^2] - 0^2 = \mathbb{E}[\epsilon^2]\).
Um den Bias-Variance Tradeoff zu zeigen, leiten wir nun den Erwartungswert des quadrierten Fehlers für eine gegebene Testbeobachtung her, die wir als \((y_0,\mathbf{x}_0)\) bezeichnen. Dies wäre der durchschnittliche quadrierte Fehler, den wir für diese Beobachtung kriegen würden, wenn wir mit jedem geschätzten Modell die Vorhersage für diese Testbeobachtung rechnen würden.
VorsichtHerleitung (optional)
In einem ersten Schritt erweitern wir den quadrierten Fehler, indem wir einmal den wahren Funktionswert an der Stelle \(\mathbf{x}_0\) abziehen und einmal hinzuzählen. Zusammen gibt das Null und verändert darum die rechte Seite der Gleichung nicht:
\[\begin{align} \mathbb{E}\left[\left(y_0 - \hat{f}(\mathbf{x}_0)\right)^2\right] &= \mathbb{E}\left[\left(y_0 - f(\mathbf{x}_0) + f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0)\right)^2\right] \end{align}\]
Nun verwenden wir die bekannte polynomische Expansion \((a+b)^2=a^2+2ab+b^2\), aber hier behandeln wir \(y_0 - f(\mathbf{x}_0)\) als \(a\) und \(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0)\) als \(b\). Dadurch kriegen wir folgende Gleichung:
\[\begin{align} \mathbb{E}\left[\left(y_0 - \hat{f}(\mathbf{x}_0)\right)^2\right] &= \mathbb{E}\biggl[\left(y_0 - f(\mathbf{x}_0)\right)^2 \\ &+ 2\left(y_0 - f(\mathbf{x}_0)\right)(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0)) \\ &+ (f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\biggr] \end{align}\]
Nun wissen wir aus obigen Annahmen, dass der Erwartungswert von \(y_0\) folgender ist: \(\mathbb{E}[y_0]=\mathbb{E}[f(\mathbf{x}_0) + \epsilon]=f(\mathbf{x}_0)\). Dadurch entfällt der erste Teil des zweiten Terms, weil \(\mathbb{E}[\left(y_0 - f(\mathbf{x}_0)\right)]=f(\mathbf{x}_0) - f(\mathbf{x}_0)=0\). Dadurch lässt sich das Ganze massiv vereinfachen zu:
\[\begin{align} \mathbb{E}\left[\left(y_0 - \hat{f}(\mathbf{x}_0)\right)^2\right] &= \mathbb{E}\left[\left(y_0 - f(\mathbf{x}_0)\right)^2\right] + \mathbb{E}\left[(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\right] \end{align}\]
Nun setzen wir im ersten Erwartungswert auf der rechten Seite anstelle von \(y_0\) den Term \(f(\mathbf{x}_0) + \epsilon\) ein und kriegen folgendes:
\[\begin{align} \mathbb{E}\left[\left(y_0 - \hat{f}(\mathbf{x}_0)\right)^2\right] &= \mathbb{E}\left[\left(f(\mathbf{x}_0) + \epsilon - f(\mathbf{x}_0)\right)^2\right] + \mathbb{E}\left[(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\right] \\ &= \mathbb{E}\left[\epsilon^2\right] + \mathbb{E}\left[(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\right] \\ &= \text{Var}(\epsilon) + \mathbb{E}\left[(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\right] \end{align}\]
Das ist schon mal ein erstes wichtiges Zwischenresultat. Der Erwartungswert des quadrierten Fehlers wird eine untere Grenze haben, die genau der Varianz des Fehlerterms, \(\text{Var}(\epsilon)\), entspricht. Diese untere Grenze des erwarteten Fehlers wird dann erreicht, wenn unser geschätztes Modell genau dem wahren entspricht und darum der zweite Term oben entfällt.
Nun wollen wir diesen zweiten Term oben noch etwas weiter aufspalten. Dazu brauchen wir wiederum den Trick, den wir oben bereits angewendet haben. Wir ziehen den Erwartungswert des geschätzten Modells \(\mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\) einmal ab und fügen ihn einmal hinzu:
\[\begin{align} \mathbb{E}\left[(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\right] &= \mathbb{E}\left[\left(f(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right] + \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right] - \hat{f}(\mathbf{x}_0)\right)^2\right] \\ &= \mathbb{E}\left[\left(f(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right] - \left(\hat{f}(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)\right)^2\right] \end{align}\]
Ähnlich wie weiter oben können wir diese Gleichung mit einer polynomischen Expansion wie folgt umschreiben:
\[\begin{align} \mathbb{E}\left[(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\right] &= \mathbb{E}\biggl[\left(f(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2 \\ &- 2\left(f(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)\left(\hat{f}(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right) \\ &+ \left(\hat{f}(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2\biggr] \end{align}\]
Auch hier entfällt der mittlere Term, wenn wir den Erwartungswert in die Klammern reinnehmen, weil der zweite Teil \(\left(\mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right] - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)=0\) ist.
Was übrig bleibt ist folgendes:
\[\begin{align} \mathbb{E}\left[(f(\mathbf{x}_0) - \hat{f}(\mathbf{x}_0))^2\right] &= \mathbb{E}\left[\left(f(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2\right] + \mathbb{E}\left[\left(\hat{f}(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2\right] \\ &= \left(f(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2 + \mathbb{E}\left[\left(\hat{f}(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2\right] \end{align}\]
Schauen wir uns kurz die beiden Komponenten auf der rechten Seite etwas genauer an:
- \(\left(f(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2\) ist der quadrierte Bias und misst die systematische Abweichung unseres geschätzten Modells \(\hat{f}\) vom wahren unbekannten Modell \(f\). Je kleiner der Bias, desto tiefer der erwartete quadrierte Fehler. Wir können diesen Term der Einfachheit halber mit \(\left[\text{Bias}\left(\hat{f}(\mathbf{x}_0)\right)\right]^2\) bezeichnen.
- \(\mathbb{E}\left[\left(\hat{f}(\mathbf{x}_0) - \mathbb{E}\left[\hat{f}(\mathbf{x}_0)\right]\right)^2\right]\) ist nichts anderes als die Varianz unseres geschätzten Modells \(\hat{f}\). Sie misst, wie stark sich \(\hat{f}\) im Schnitt verändert, wenn wir einen anderen Datensatz für das Training verwenden. Ein Modell mit hoher Varianz passt sich jeweils sehr stark an die Daten an. Je kleiner diese Varianz, desto tiefer der erwartete quadrierte Fehler. Wir bezeichnen diesen Term der Einfachheit halber als \(\text{Var}\left(\hat{f}(\mathbf{x}_0)\right)\).
Nun sind wir endlich am Ziel angelangt und können den erwarteten quadrierten Fehler für die Beobachtung \((y_0,\mathbf{x}_0)\) wie folgt aufschreiben:
\[ \mathbb{E}\left[\left(y_0 - \hat{f}(\mathbf{x}_0)\right)^2\right] = \text{Var}(\epsilon) + \left[\text{Bias}\left(\hat{f}(\mathbf{x}_0)\right)\right]^2 + \text{Var}\left(\hat{f}(\mathbf{x}_0)\right) \]
Der erwartete quadrierte Fehler für die Beobachtung \((y_0,\mathbf{x}_0)\) kann wie folgt beschrieben werden:
\[ \mathbb{E}\left[\left(y_0 - \hat{f}(\mathbf{x}_0)\right)^2\right] = \text{Var}(\epsilon) + \left[\text{Bias}\left(\hat{f}(\mathbf{x}_0)\right)\right]^2 + \text{Var}\left(\hat{f}(\mathbf{x}_0)\right) \]
- Ein Modell mit viel Bias, also \(\text{Bias}\left(\hat{f}(\mathbf{x}_0)\right)\), führt zu einer schlechten Vorhersagequalität (auf Trainings- und Testdaten), weil das Modell zu rigide ist, um den wahren Zusammenhang zwischen der Output-Variable und den Input-Variablen zu modellieren. Beispiel: wir verwenden ein einfaches lineares Regressionsmodell, um einen stark nicht-linearen Zusammenhang zwischen \(y_i\) und \(\mathbf{x}_i\) zu modellieren. Im Fall von Modellen mit viel Bias spricht man auch von Underfitting.
- Ein Modell mit viel Varianz führt zu einer hervorragenden Vorhersagequalität auf den Trainingsdaten, aber zu einer sehr schlechten Vorhersagequalität auf den Testdaten. Das Problem hier ist, dass das Model zu flexibel ist gemessen an der Grösse des Trainingsdatensatzes. Das Modell passt sich so zu stark an die Trainingsdaten an und modelliert auch sogenanntes Noise, also \(\epsilon\) (und nicht nur das Signal in den Daten). Beispiel: wir modellieren ein neuronales Netzwerk, haben aber nur einen Trainingsdatensatz von einigen hundert Beobachtungen. Im Fall von Modellen mit viel Varianz spricht man auch von Overfitting.
- Der dritte Term, \(\text{Var}(\epsilon)\), ist die Varianz des Fehlerterms. Es ist der nicht-reduzierbare Teil des erwartbaren Vorhersagefehlers, d.h., wir erwarten selbst wenn wir das bestmögliche Modell gefunden haben einen gewissen Fehler.
Warum spricht man von einem Tradeoff? Flexiblere Modelle haben oft einen kleinen Bias, aber hohe Varianz, während unflexible Modelle oft eine kleine Varianz, aber einen hohen Bias haben. Es existiert also ein Tradeoff zwischen Bias und Varianz und wir wollen beim Modellieren und vor allem beim Hyperparameter Tuning (zum Beispiel \(\lambda\)) den optimalen Tradeoff finden.
Regularisierte Regression revisited
Der Hyperparameter \(\lambda\) spielt bei der regularisierten Regression eine zentrale Rolle für den Tradeoff zwischen Bias und Variance. Ein zu tiefer Wert für \(\lambda\) kann zu einem zu flexiblen Modell mit viel Varianz führen. Ein zu hoher Wert für \(\lambda\) führt zu einem zu rigiden Modell mit viel Bias.
Im folgenden Beispiel haben wir \(n = 50\) Beobachtungen. Die Daten wurden durch folgenden Prozess generiert:
\[ y_i = 2 + 1 \cdot x_{i,1} + \epsilon_i \] wobei \(\epsilon_i \sim N(0, 0.2)\). Das wahre Modell ist dementsprechend \(f(\mathbf{x}_i) = 2 + 1 \cdot x_{i,1}\).
Der Datensatz enthält aber 49 weitere Prädiktoren \(x_{i,2}, x_{i,3}, \dots, x_{i,50}\), welche nicht mit der Output-Variable \(y_i\) korreliert sind. Als Analyst:in wissen Sie das jedoch nicht. Sie sehen lediglich die 50 Input-Variablen und die Output-Variable.
Folgende Abbildung zeigt die Resultate von vier LASSO Modellen mit unterschiedlichen Werten für \(\lambda\).
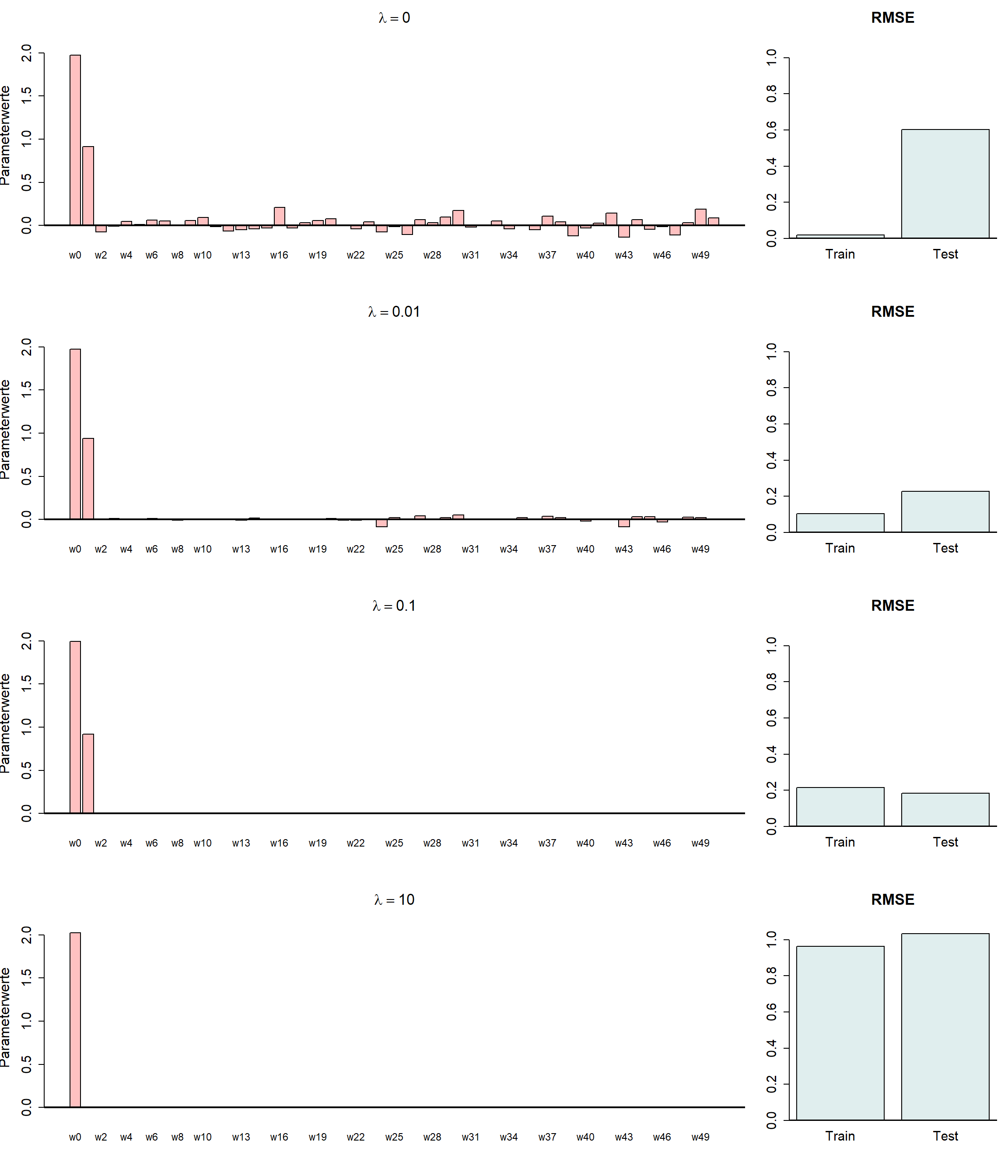
Frage
Welches der vier abgebildeten Modelle mit entsprechendem Wert für \(\lambda\) ist optimal?
TippLösung
Das dritte Modell mit \(\lambda = 0.1\) ist optimal. Wir sehen, dass in diesem Fall nur die Gewichte \(w_0 \approx 2\) und \(w_1 \approx 1\) nicht Null sind. Ausserdem sind die beiden RMSE Werte auf Trainings- und Testdaten ähnlich und auf tiefem Niveau.
Das erste Modell (\(\lambda = 0\)) entspricht der Kleinstquadratemethode und ist ein gutes Beispiel für Overfitting. Das Modell verwendet alle 50 Input-Variablen und kann so den RMSE auf den Trainingsdaten fast auf 0 reduzieren. Der Testdaten-RMSE ist dann aber vergleichsweise hoch - ein typisches Zeichen von Overfitting.
Der vierte Modell (\(\lambda = 10\)) ist ein perfektes Beispiel von Underfitting. Der Regularisierungsterm \(\lambda\) ist so gross, dass nur noch ein Modell mit einer Konstante \(w_0 \approx 2\) geschätzt wurde. Entsprechend sind sowohl der RMSE auf den Trainingsdaten als auch der RMSE auf den Testdaten hoch - ein typisches Zeichen von Underfitting.
Das zweite Modell ist nicht schlecht, aber zeigt immer noch leichte Anzeichen von Overfitting.
Wichtig:
- Indem wir den Hyperparameter via Resampling (z.B. K-Fold Cross Validation, später mehr dazu) optimieren, wählen wir automatisch ein Modell mit einem guten Tradeoff zwischen Bias und Varianz!
- Mit grossen Datensätzen ist das Problem des Overfittings weniger dramatisch. Haben wir genügend Trainingsdaten, dann können selbst flexible Modelle nicht zu stark overfitten. Die Anzahl Trainingsdaten hat also einen regulierenden Einfluss.
Eine letzte Überlegung bezüglich Modellselektion geht folgendermassen: wenn wir mehrere Modelle haben, die ähnlich gut performen, dann wählen wir das einfachste (kleinste) oder am wenigsten komplexe Modell. Man nennt dies Occam’s Razor. William of Occam war ein Englischer Mönch und hat dieses Prinzip in einem anderen Kontext erstmals formuliert.
2.7 Polynomische Regression
Wir machen hier nun einen kurzen Abstecher und lernen die polynomische Regression kennen, denn diese eignet sich auch sehr gut, um den Bias-Variance Tradeoff zu illustrieren.
Das polynomische Regressionsmodell sieht im Fall von einer Input-Variable \(x_i\) folgendermassen aus:
\[ y_i = w_0 + w_1 \cdot x_i^1 + w_2 \cdot x_i^2 + w_3 \cdot x_i^3 + \dotsb + w_M \cdot x_i^M + \epsilon_i \]
Es handelt sich also um ein Regressionsmodell wie wir es kennen gelernt haben, einfach mit den Polynomen von \(x_i\) bis zum \(M\)-ten Grad als Input-Variablen.
Mit einem Datensatz der Grösse \(n\), kann ein polynomisches Regressionsmodell mit Grad \(M = n−1\) die Daten perfekt abbilden. Das Modell hat in diesem Fall so viele Freiheitsgrade wie der Trainingsdatensatz Beobachtungen hat. Dabei handelt es sich um ein extremes Beispiel von Overfitting.
Wir sehen in untenstehender Abbildung drei Fälle einer polynomischen Regression. Die schwarze Kurve zeigt das wahre Modell, von dem die blauen Datenpunkte unter Hinzufügen von etwas Noise generiert wurden. Die braune Kurve zeigt das jeweils geschätzte Modell. Rechts sehen Sie ähnlich wie oben jeweils den RMSE auf Trainings- und auf Testdaten.
Folgende Punkte gilt es festzuhalten:
- Das erste Modell ist eine polynomische Regression mit Grad \(M=0\), in der nur die Konstante \(w_0\) in das Modell einfliesst. Ein klarer Fall von Underfitting.
- Das zweite Modell ist eine polynomische Regression mit Grad \(M=9\), das mit \(n=10\) Beobachtungen trainiert wird - das bereits angesprochene Beispiel von extremem Overfitting.
- Beim dritten Modell zeigt sich der regulierende Effekt von mehr Trainingsdaten. Das komplexe Modell mit \(M=9\) führt im Fall von \(n=100\) Trainingsbeobachtungen zu einem sehr guten Fit.
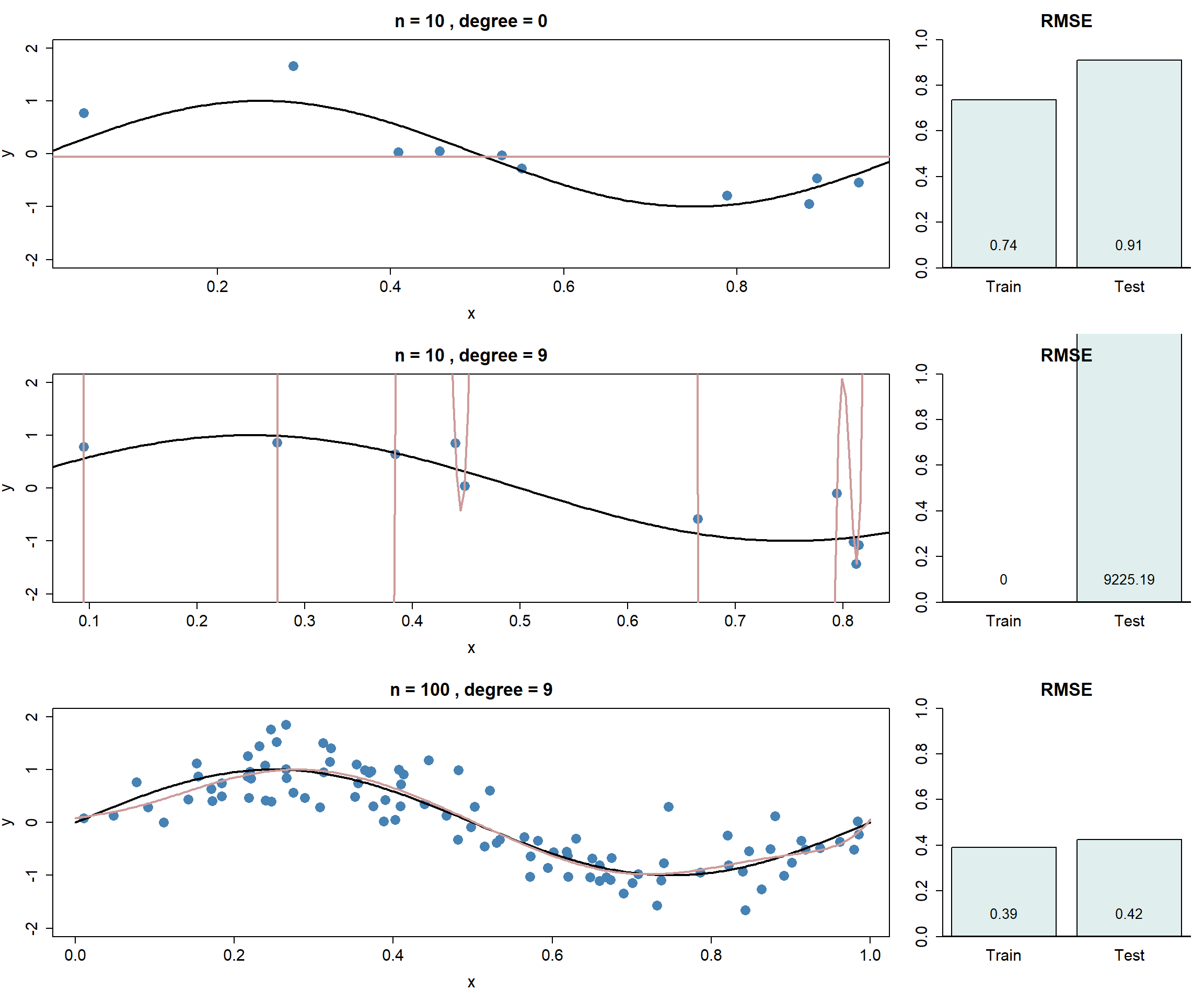
Wichtig: das polynomische Regressionsmodell ist immer noch linear in den Parametern, es handelt sich also immer noch um ein lineares Modell. Sie sehen aber an obigen Modellkurven, dass dieses “lineare” Modell sehr wohl in der Lage ist, nicht-lineare Zusammenhänge zwischen \(x\) und \(y\) zu fitten!
2.8 Lineare Regression in R
2.8.1 Base R
In Base R lassen sich Regressionsmodelle einfach mit der lm() Funktion (lm steht für linear model) rechnen.
# Datenpunkte
x <- c(-4.1, -0.5, 1.4, 4.4)
y <- c(3.5, 1.95, -2.5, -2.05)
# Dataframe
df <- data.frame(x = x, y = y)
# Modellrechnung (Kleinsquadrateschätzer)
mod <- lm(y ~ x, data = df)
# Modelloutput
summary(mod)
Call:
lm(formula = y ~ x, data = df)
Residuals:
1 2 3 4
0.02129 1.13342 -1.91157 0.75686
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.4468 0.8340 0.536 0.646
x -0.7395 0.2692 -2.747 0.111
Residual standard error: 1.66 on 2 degrees of freedom
Multiple R-squared: 0.7904, Adjusted R-squared: 0.6857
F-statistic: 7.544 on 1 and 2 DF, p-value: 0.1109Der obige R Output ist der klassische Regressionsoutput der lm() Funktion. In der Spalte Estimate sehen wir insbesondere die geschätzten (trainierten) Modellparameter.
Wir können unser geschätztes Modell nun wie folgt verwenden, um Vorhersagen für zwei neue Input-Variablenwerte (2.5 und 5.1) zu machen.
# Modellvorhersagen
yp <- predict(mod, newdata = data.frame(x = c(2.5, 5.1)))
yp 1 2
-1.401854 -3.324500 2.8.2 tidymodels + glmnet
Für regularisierte Regressionsmodelle eignet sich der tidymodels Framework in Kombination mit glmnet (letzteres ist die Engine für regularisierte Modelle aller Art). Wir laden als erstes die beiden Packages. Beim ersten Mal müssen diese Packages mit install.packages(c("tidymodels", "glmnet")) installiert werden.
library(tidymodels)
library(glmnet)Wir generieren hier dieselben Daten wie in einer der Demos oben, wo wir die regularisierte Regression demonstriert haben. Die Daten werden wie oben nach folgendem Modell generiert:
\[ y_i = 2 + 1 \cdot x_{i,1} + \epsilon_i \] Der folgende Code-Block generiert die Daten:
# Seed für Reproduzierbarkeit
set.seed(123)
# Wir definieren die Anzahl Beobachtungen, die Anzahl Input-Var.
# und die Standardabweichung des Fehlerterms.
n <- 50
p <- 50
sd <- 0.2
# Nun simulieren wir die Input-Variablenwerte aus einer Normalverteilung.
Xtrain <- matrix(rnorm(n * p), nrow = n)
# Generierung der y-Werte mit normalverteiltem Noise.
ytrain <- 2 + Xtrain[, 1] + rnorm(n, 0, sd)
# Wir fassen die Input-Variablen und den Output zu einem Dataframe zusammen.
train <- as.data.frame(Xtrain)
train$y <- ytrainIm folgenden Code verwenden wir tidymodels, um ein lineares Regressionsmodell mit linear_reg() zu initialisieren. In tidymodels heisst der Hyperparameter \(\lambda\) penalty und mit mixture = 1 definieren wir, dass ein LASSO Modell gerechnet werden soll (mixture = 0 würde einem Ridge Modell entsprechen).
# Modellspezifikation für lineares Modell mit Regularisierung
lm_mod <-
linear_reg(penalty = 0.1, mixture = 1) |>
set_engine("glmnet")Nun fitten wir das Modell mit fit(). Mit formula = y ~ . legen wir fest, dass y die Outputvariable ist und dass alle anderen Variablen im Dataframe train als Input-Variablen verwendet werden sollen.
# Modelltraining
lm_fit <-
lm_mod |>
fit(formula = y ~ ., data = train)Nun können wir uns noch die trainierten Modellparameter (in der Spalte estimate) anschauen.
# Parameter des Modells
tidy(lm_fit) %>%
print(n = 51)# A tibble: 51 × 3
term estimate penalty
<chr> <dbl> <dbl>
1 (Intercept) 2.00 0.1
2 V1 0.887 0.1
3 V2 0 0.1
4 V3 0 0.1
5 V4 0 0.1
6 V5 0 0.1
7 V6 0 0.1
8 V7 0 0.1
9 V8 0 0.1
10 V9 0 0.1
11 V10 0 0.1
12 V11 0 0.1
13 V12 0 0.1
14 V13 0 0.1
15 V14 0 0.1
16 V15 0 0.1
17 V16 0 0.1
18 V17 0 0.1
19 V18 0 0.1
20 V19 0 0.1
21 V20 0 0.1
22 V21 0 0.1
23 V22 0 0.1
24 V23 0 0.1
25 V24 0 0.1
26 V25 0 0.1
27 V26 0 0.1
28 V27 0 0.1
29 V28 0 0.1
30 V29 0 0.1
31 V30 0 0.1
32 V31 0 0.1
33 V32 0 0.1
34 V33 0 0.1
35 V34 0 0.1
36 V35 0 0.1
37 V36 0 0.1
38 V37 0 0.1
39 V38 0 0.1
40 V39 0 0.1
41 V40 0 0.1
42 V41 0 0.1
43 V42 0 0.1
44 V43 0 0.1
45 V44 0 0.1
46 V45 0 0.1
47 V46 0 0.1
48 V47 0 0.1
49 V48 0 0.1
50 V49 0 0.1
51 V50 0 0.1Vorschlag: Kopieren Sie die Codezeilen in ein lokales Skript und probieren Sie andere Werte für den Hyperparameter \(\lambda\) (penalty) aus.
\(\epsilon = y_i - f(\mathbf{x}_i)\)↩︎
So müssen wir die Konstante \(w_0\) nicht separat aufschreiben.↩︎
Das Quadrieren führt dazu, dass grosse Differenzen die gesamte Summe der quadrierten Fehler dominieren.↩︎
Falls Sie den optionalen Teil “Kleinsquadratemethode in Matrixform” angeschaut haben: in diesem Fall ist die Matrix \(\mathbf{X}'\mathbf{X}\) nicht invertierbar.↩︎
Formel für die Standardisierung: \(\frac{y_i-\bar{y}}{s_y}\)↩︎
LASSO ist die Abkürzung für least absolute shrinkage and selection operator↩︎